





提高阅读效率——利用机器学习的网页正文提取方法
出处:安增文, 王 超, 徐杰锋 发布于:2011-08-31 09:03:27
互联网的普及使得网络成为人们获取信息的重要途径。而互联网上的信息量也与日俱增,网页上的内容除了主题内容外,通常都会在页面中放置导航条以方便用户访问,还有如广告、版权信息、欢迎信息等与主题无关的内容,我们称之为“噪音”.
怎样去除这些噪音,将网页中的正文内容提取出来,从而提高人们的阅读效率,这在垂直搜索和数据挖掘方面具有重要意义。在这个领域已经发表了很多的研究成果,这些研究成果从不同的角度入手,有的只利用网页本身的特征,有的还与其他技术相结合,使网页正文抽取的准确性和完整性得到不断提高,但还没有一种方法能达到人们期望的程度,还需要不断地研究和探索。
一、正文抽取相关研究
到目前为止,已经发表的网页正文内容抽取方法有很多种,其分类方式的依据也不尽相同,下面介绍几种较为常用的抽取方法。
1、基于模板的方法
这种技术依赖HTML文档的内部结构特征来完成数据抽取,需要使用wrapper(包装器)来抽取网页中的正文内容。包装器可以通过分析网页源代码来手工编写,也可以通过程序自动或半自动的实现。手工编写的方法一般都针对特定的网页模式,其优点是实现简单、准确率高,缺点是对于不同的网页模式或网页结构发生变化时需要重新编写包装器,如果包装器类型很多,包装器的维护代价会很大,但由于该方法的准确性较高,所以在针对特定网站的抽取中应用很广。自动或半自动地生成包装器的方法在一定程度上减轻了维护包装器的工作量,但是需要样本学习,对用户要求较高。
2、基于统计的方法
这种方法从页面的不同角度分析它的统计特征,采用统计学的算法抽取正文。例如根据统计的文字数量、链接数量、标签字符数量等计算出文本密度、链接密度等,并通过这些值来判断哪些为正文文本、哪些为噪音内容。参考文献[1]提出一种通过分析页面文本密度进行正文抽取的方法。这种方法实现简单,并且不需要编写包装器,但提取的准确率有限,有时会将与正文无关的版权声明等当作正文内容提取出来。
3、基于神经网络的方法
由于神经网络具有优越的非线性处理能力和泛化能力,因此在很多实际领域中都取得了传统符号学习机制难以获得的效果。搜索结点的输入连接权,通过找出权值之和超过阈值的连接权子集来抽取规则。利用多层网络度量输入之间的接近程度,并利用单层抑制性网络度量输入、输出相关度,从而获得抽取规则。
针对新闻类网页及类似布局的页面,在对页面文本密度进行统计之后对文本密度与页面标题、正文之间的对应关系进行分析,以对传网络(CPN)为工具,对文本密度在标题、正文等语义块中的分布模式进行拟合,从而达到抽取目标信息的目的。
4、基于中文标点符号和HTML树
结构的网页正文信息抽取方法HTML( hyper text markup language) 是超文本标记语言, 是基于标准通用标记语言(SGML) 的一个庞大的文档处理系统。 SGML 的基本思想是采用描述标记( Tag) 来提供描述文档结构的附加信息。 HTML 利用SGML 定义了一些标记,如<html>、<title>等,用于描述文本的显示方式,并对这些标记的使用都做了格式定义,对于实体符号的显示和标记元素的结构也做了规范,使得HTML 网页在文本格式和结构上存在一定的规律,也为网页信息的提取提供了方便。
在规范化之前,可以先删除<form>、<script>和<style>等用于控制HTML 文件的交互性和显示的标记,这些标记不包含主题内容,剔除后可加快处理速度。 使用HTML Tidy 工具对网页进行规范化可以实现完整的HTML 树结构的显示,但没有针对性和可操作性,所以编写了用于本文研究的HTML 规范化程序,然后通过HTML 树解析程序将规范的HTML 文件解析成HTML树,树中的每个结点包含了一对标记间的所有字符,结点的名字为对应标记的名字。
以行为单位对网页源代码中的每一行计算其相关的六个属性,并以此作为BP神经网络的输入参数进行学习。由于该算法未对文本内容和标题的相关度进行判断,所以导致会将一些网站的版权声明当作正文内容错误地提取出来。所以通过计算文本内容和标题的相关度来区别是否为噪音是合理的。本方法以行为单位对DOM树进行处理,将每行的文本密度、文本内容与标题的相关度作为输入参数利用BP神经网络进行训练,从而提高信息抽取的准确度。
二、算法描述
1、BP神经网络模型
BP算法属于Delta学习规则,是一种有教师的学习算法,是以网络误差平方和为目标函数,按梯度法(gradient approaches)求其目标函数达到值的算法。一个典型的BP神经网络包括:(1)由一个输入层x、一个(或多个)隐藏层y和一个输出层o组成的三层或多层结构;(2)处理单元(图1中的圆圈)是网络的基本组成部分,输入层的处理单元只是将输入值转入相邻的联接权重,隐层和输出层的处理单元将它们的输入值求和并根据传递函数计算输出值;(3)联接权重(如图1中v,w)将神经网络中的处理单元联系起来,其值随各处理单元的连接程度而变化;(4)阈值,其值可为恒值或可变值,它可使网络能更自由地获取所要描述的函数关系;(5)传递函数F,它是将输入的数据转化为输出的处理单元,通常为非线性函数。
输入层和输出层的结点个数可以根据训练集来确定,而隐藏层的结点却需要试验判断。如果隐藏层结点数过少,网络就不能具有必要的学习能力和信息处理能力。如果隐藏层结点数过多,不仅会大大增加网络结构的复杂性,网络在学习过程中更易陷入局部极小值,而且会使网络的学习速度变得很慢。
2、利用人工神经网络进行正文提取
网页的类型大体上可以分为三类:
(1)文字多图片少的内容型网页,如新闻网页;
(2)以图片为主文字介绍为辅的图片型网页,如图片新闻;
(3)以超链接为主的目录型网页,如新浪。试验中我们以内容型网页作为主要研究对象。
三、网页源文件预处理
随着web2.0的发展,网站为了定制网页的表现形式和提高网页视觉效果,在源文件中加入大量Script脚本和CSS代码。所以在抽取正文之前要对网页源文件进行预处理,去除与正文内容不相关的噪音内容。
首先,由于html语言书写的随意性,导致有些网页源代码的不规范,例如标签对缺失、嵌套不准确等。所以要将缺失的html标签补齐、修改不正确的嵌套关系,并将源代码转换为DOM树的形式。本文采用HTML Tidy工具来处理网页。
其次,要判断网页源文件的编码,否则有可能抽取到乱码。以源文件头中的meta里声明的charset为准,对于编码为GBK、gb2312等格式的网页,都将其转为utf8格式。
,Script标签对之间和CSS内容都与正文内容无关,要全部删除。另外,对于<a></a>等无用的空标签对也一并删除。
四、神经网络训练过程
1、页面主题的提取
<title>中的内容一般为文章标题,但现在各大网站一般采用“文章标题+网站名”的形式放在<title>标签中,且用符号“-”或“_”连接。在此将<title>中的文字内容取出,并将“-”或“_”符号后面的文字删除;若有多个这种符号,则将一个这种符号后面的文字内容删除,剩下的文字内容作为文章标题。因为标题中的文字内容一般会在正文内容中出现,而非正文内容一般不会包含标题词,所以可以将文本内容与文章标题的相关度作为判断文本是否正文的一个因子。
2、统计各项值
以行为单位对DOM树进行处理,依次统计每行的文本长度y和字符总长度z,用p表示该段的文本密度,则p=y/z,该行的文本内容为c.
3、计算相关度
分别对文章标题t和每行取出的文本内容c进行分词,得到对应的标题词项(t1,t2…tm)和文本词项(c1,c2…cn),然后将每个标题词项ti和文本词项cj进行匹配,统计匹配次数并进行加权计算,得出其相关度,记相关度为s.为了提高相关度的准确性,本文借鉴搜索引擎中“倒排索引”的经验,对“的”“是”等停止词放在词库中进行分词,但不对其进行相关度计算。
采用BP神经网络作为训练模型,各层的激励函数均为logsig,目标误差设为0.05,学习率为0.2.该模型有12个输入结点、5个隐藏层结点和一个输出结点。其中12个输入参数为:每行的文本长度、每行的字符总长度、每行的文本密度、每行文本内容与标题的相关度、上一行的这四个值和下一行的这四个值。具体步骤如下:
(1)获取训练集并做好标记。
(2)对网页源文件进行预处理,生成相应的DOM树。
(3)从DOM树中读取一行文字,统计相应值,得出输入向量和期望输出。
(4)输入向量经过隐藏层结点和输出层结点的传递函数得到实际输出。
(5)计算实际输出向量和期望输出向量的误差,并计算各输出误差项和隐藏层结点误差项。如果误差在允许范围内,则回到步骤(3),从DOM树中读取下一行文字继续进行。如果误差不在允许误差范围内,则根据计算出的误差项计算出各权重的调整量,并调整权重。
(6)返回步骤(4),继续迭代,直到实际输出向量和期望输出向量的误差满足要求。返回步骤(3)读取下一行内容,继续进行学习。
(7)标签树遍历完毕,训练结束。
将DOM树的各个元素偶对的相关值作为神经网络的输入,样本标记结果作为输出,通过学习算法自动生成抽取规则,对新的页面应用抽取规则进行测试。
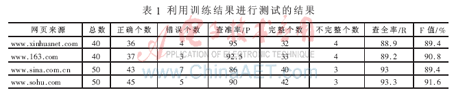
五、测试结果
采用信息抽取技术中常用的查全率(R)、查准率(P)和F值三个评价指标对测试结果进行评价。查全率表示被正确抽取的信息的比例、查准率表示提取出来的正确信息的比率、F值是查全率和查准率的加权几何平均值。用公式表示如下:P=(正确抽取出正文内容的网页数/总网页数)*100%,R=(抽取出完整正文内容的网页数/正确抽取出正文内容的网页数)*100%,在此将查全率和查准率看的同等重要,得出F=2PR/(P+R)。根据F值与1的靠近程度来判断算法的好坏,越靠近1算法越好。
从几大新闻网站随机抽取20个网页进行人工分析和标记,按照以上方法进行训练。为了测试抽取方法的可行性,再抽取一定量的网页作为测试集,并利用训练结果进行测试。测试结果如表1所示。
在本文中通过统计DOM树每一行的文本长度和字符长度,进而计算文本密度以及文字内容与标题的相关度,并将这些数值作为输入参数输入到人工神经网络进行训练。通过计算内容和标题的相关度可以避免将一些标签字符较少、文字内容较多的版权声明等内容提取出来,进而提高正文抽取的准确度。从测试结果看,该方法具有一定的可行性。下一步要寻求更好的相关度计算方法,更准确地计算正文和标题的相关度,进一步提高正文抽取的准确性。
版权与免责声明
凡本网注明“出处:维库电子市场网”的所有作品,版权均属于维库电子市场网,转载请必须注明维库电子市场网,https://www.dzsc.com,违反者本网将追究相关法律责任。
本网转载并注明自其它出处的作品,目的在于传递更多信息,并不代表本网赞同其观点或证实其内容的真实性,不承担此类作品侵权行为的直接责任及连带责任。其他媒体、网站或个人从本网转载时,必须保留本网注明的作品出处,并自负版权等法律责任。
如涉及作品内容、版权等问题,请在作品发表之日起一周内与本网联系,否则视为放弃相关权利。
- 网桥是什么_网桥如何设置2024/4/12 17:39:56
- TEC 控制器在电信系统中的应用指南2024/4/8 17:43:07
- 什么是5G NR技术?2024/4/8 17:31:58
- OFDMA基本原理2024/4/7 17:45:04
- 一文读懂3GPP到底是什么2024/4/1 17:46:30



