|
|||||||||||
| 技术交流 | 电路欣赏 | 工控天地 | 数字广电 | 通信技术 | 电源技术 | 测控之家 | EMC技术 | ARM技术 | EDA技术 | PCB技术 | 嵌入式系统 驱动编程 | 集成电路 | 器件替换 | 模拟技术 | 新手园地 | 单 片 机 | DSP技术 | MCU技术 | IC 设计 | IC 产业 | CAN-bus/DeviceNe |
请教高手:声音的变速不变调是怎样实现的?? |
| 作者:busy 栏目:单片机 |
有些学习机有播放调速功能(例如快、慢速播放),而它的音调却不变! 请问大虾们,这是什么样的原理呢?是否有源代码参考? 谢谢! 欢迎讨论。 zby8020@163.com |
| 2楼: | >>参与讨论 |
| 作者: busy 于 2005/6/29 9:22:00 发布:
自己顶顶 |
|
| 3楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/6/29 9:25:00 发布:
很久没灌技术水了,国内的学习机就以这一点技术作为买点 我就把它点破,希望对有志于搞英文学习机的朋友有帮助。 点破不值一文钱! 我首先用条件作假设,排除所有可能,余下的就是唯一了,是不是分析得很神奇? 我又准备吹牛了。。。。 不过这个贴子我会过一阵再回,先吊一下大家的胃口。。。。。不知道有多少人对这个原理有兴趣的。。。。 发技术贴是有代价的,就看有多少的学徒了!。。。。想知道原理的就狂顶吧! * - 本贴最后修改时间:2005-6-29 9:30:47 修改者:宇宙飞船 |
|
| 4楼: | >>参与讨论 |
| 作者: busy 于 2005/6/29 9:44:00 发布:
恳请宇宙飞船高人指点啊..... 这个问题已经困惑我很久了! 望知道的高人指点啊! |
|
| 5楼: | >>参与讨论 |
| 作者: busy 于 2005/6/29 10:47:00 发布:
在线等高人的出现.............. 555555555555555555555555 |
|
| 6楼: | >>参与讨论 |
| 作者: chunyang 于 2005/6/29 11:13:00 发布:
既然飞船打算“吊一下大家的胃口”,不敢打扰雅兴 稍透一点风:多年前,就有专用芯片,模拟的,现在都用数字技术了,实现起来更简单,(以下省略300字),等飞船来给大家指点迷津。 |
|
| 7楼: | >>参与讨论 |
| 作者: 潜艇8421 于 2005/6/29 11:16:00 发布:
好象想知道的人不多。。。! 我劝飞船还是单独发电子邮件到楼主信箱,免得做英语学习机的找您算账。。。。 |
|
| 8楼: | >>参与讨论 |
| 作者: busy 于 2005/6/29 11:22:00 发布:
我查了下,好象与专利权有关.... 音频信号保真变速处理方法: 本发明涉及一种音频信号保真变速处理方法,包括保真慢放处理和保真快放处理方法。传统的改变放音速度的技术,通常通过改变放音机的走带速度来实现,其缺点是会导致音调音色变化。本发明提供一种保真变速处理方法,它包括:将数字音频信号进行切割分段;在部分或全部小段后插入至少一段信息单元,以延长音频信号,或者,间隔地将部分小段删除,将未删除的小段紧缩连接,以缩短音频信号。 (未尽详细) |
|
| 9楼: | >>参与讨论 |
| 作者: zhousd 于 2005/6/29 11:36:00 发布:
好玩的贴子! 这原理对chunyang 前辈来说当然是小菜一碟,说不定专利就是前辈申请的。。。 |
|
| 10楼: | >>参与讨论 |
| 作者: chunyang 于 2005/6/29 11:43:00 发布:
楼上说得太离谱了 原理我是知道一些,不过没有飞船精通,还是请他给大家说说吧。 busy的习惯不错,有问题先搜搜。 |
|
| 11楼: | >>参与讨论 |
| 作者: 王命天涯 于 2005/6/29 12:11:00 发布:
. 宇宙飞船网友 在他的大作中提到: “ 我首先用条件作假设,排除所有可能,余下的就是唯一了,是不是分析得很神奇?” 呵呵,笑煞我了, 。。。 看到这句话, 让我想到一个人来,老顽童周伯通 出场的时候用的基本上就是这样的台词和口吻。。。 特别是 “是不是分析得很神奇?” 这句。。简直是妙极。 支持讲述原理 -_-!! |
|
| 12楼: | >>参与讨论 |
| 作者: honsing 于 2005/6/29 12:35:00 发布:
或许用DSP可以实现 我见过一款创新的声卡就是通过声卡上自带的DSP进行声音的一些变换,比如,把男声变成女声,把女声改成男声等等,至于变速不变调倒没有在意有没有这个功能。 |
|
| 13楼: | >>参与讨论 |
| 作者: hover_z 于 2005/6/29 12:49:00 发布:
想想 声音文件的存储是按点存的,播放时自然也是按点放的,就象比较老的24贞/秒的电影,如播放时时间间隔等于录时时间间隔,就是正常,如播放时时间间隔小于录时时间间隔,就是快放,如播放时时间间隔大于录时时间间隔,就是慢放,所以可以调整这个间隔时间来改变。 |
|
| 14楼: | >>参与讨论 |
| 作者: xieyuanbin 于 2005/6/29 13:03:00 发布:
我想很简单的: 如加速一倍,那么声音的频率降低一半。具体只需将采样频率降低一半就可以了。用DSP音频处理芯片很容易实践,毕竟语音的频率都在7K以下。 |
|
| 15楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/6/29 13:50:00 发布:
楼上两位还是不得要领,难怪这一点技术在中国竟然能 申请到专利,这些都是破技术,对我来说不值一分钱,等这贴子先热一会再说不迟,哈哈。。。。! chunyang老前辈也不要那么谦虚了,老前辈是我的老师,日后还得向老前辈多多讨教。 告诉大家一个好消息,刚才收到贴主的站内消息说他正准备贴PDF的有用文档出来! 先睹为快! |
|
| 16楼: | >>参与讨论 |
| 作者: busy 于 2005/6/29 14:17:00 发布:
看了这么‘多’老前辈的指点...... 小生倒是有点开窍了....哎呀......不对噎......应该看到了你们的精彩表演! 唉,可叹,还是小生的功力尚浅,不足以了解而学不到那么多老前辈的上乘武学啊!55555555555555 TO:ALL MP3的文件格式是固定的,位流也定了,那该怎么样去实现这“变速不变调”呢? 当然加快播放位流,或者跳跃式播放,都将不能保证“变速不变调”啊! 那慢放呢,播播停停吗?这好象更加不行吧?! 再说MP3固件解码器也是默认播放固定位流的MP3文件....... 5555555555555 |
|
| 17楼: | >>参与讨论 |
| 作者: hotpower 于 2005/6/29 14:22:00 发布:
静等火星人喷火(最好能喷货) |
|
| 18楼: | >>参与讨论 |
| 作者: sunshine98 于 2005/6/29 14:52:00 发布:
有这么难吗??有意思呀~~~ 凑个热闹先~~~ |
|
| 19楼: | >>参与讨论 |
| 作者: busy 于 2005/6/29 15:04:00 发布:
高高高人,你在哪...... 只盼:“蓦然回首,那人却在灯火斓珊处......” |
|
| 20楼: | >>参与讨论 |
| 作者: xwj 于 2005/6/29 15:49:00 发布:
创新的声卡十年前就有这功能了 SB Live及以后的系列都就有这功能 原理并不复杂,用DSP的动动脑筋也可以自己设计出来 |
|
| 21楼: | >>参与讨论 |
| 作者: winsu 于 2005/6/29 15:59:00 发布:
用数字处理主 把语音分割,识别语音与静音(模拟时用电平高低,数字?),语音的按正常速度播放,静音时就延时. -----猜的. |
|
| 22楼: | >>参与讨论 |
| 作者: winsu 于 2005/6/29 16:02:00 发布:
猜猜 把语音分割,识别语音与静音(模拟时用电平高低,数字?),语音的按正常速度播放,静音时就延时. -----猜的. |
|
| 23楼: | >>参与讨论 |
| 作者: busy 于 2005/6/29 16:13:00 发布:
哎,高人们,最好是爆点料,别老是说表面上的东西好吗? 盼伟大的高人出现......... |
|
| 24楼: | >>参与讨论 |
| 作者: 32768Hz 于 2005/6/29 16:27:00 发布:
不知这样行不行? 不管什么语音,都是由一定频率的正弦波组成。我们只要取每个周期,把它放3次(假如这里的速度是原来的1/3),这样不就是变速不变调吗?还望高人明示. |
|
| 25楼: | >>参与讨论 |
| 作者: busy 于 2005/6/29 16:52:00 发布:
学习机播放的MP3是可以变速的 再说学习机里肯定是用固件MP3芯片,所以不存在软件识别“什么正弦波”,除非你自己在软件里解码MP3文件,得到“什么正弦波”再处理! 我想应该是数字方面的处理,可是就是不得要领啊~~~~~~~~~~ 我期待中的高人,你....... |
|
| 26楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/6/29 17:19:00 发布:
32768HZ 已经看到了一点点的边了,请楼主别急。。。 耐点性子吧,这个贴子看来会非常好玩。。。。 21IC这里的高人多得很。。。。 * - 本贴最后修改时间:2005-6-29 17:22:28 修改者:宇宙飞船 |
|
| 27楼: | >>参与讨论 |
| 作者: lishuanghua 于 2005/6/29 17:38:00 发布:
我不懂其原理,我猜想: 先将声音的包络线和频率分离出来,改变包络线的速度,再调整到原来的频率上,不知是否可行? |
|
| 28楼: | >>参与讨论 |
| 作者: 19860622 于 2005/6/29 18:15:00 发布:
本人见到最神的技术 声音可沿直线传送,大家信吗?我自已都有不信啊! |
|
| 29楼: | >>参与讨论 |
| 作者: winhiwang 于 2005/6/29 18:22:00 发布:
建议你用WINDOWS下的声音编辑软件做个实验, 我没有做过类似的设计,但是感觉通过重复某段频率,就可以加长声音了但不变调.就象你自己把声音放慢了说一样,自己体会一下吧. |
|
| 30楼: | >>参与讨论 |
| 作者: iQanolog 于 2005/6/29 18:39:00 发布:
虽然所有的回复意义还不大 但确实非常有用。比如,....比如,....我想很慢很慢地品味飞船升空的声音,可是音调又不能变,谐波又适中,....太有意思了。许多许多年前就想拥有它 |
|
| 31楼: | >>参与讨论 |
| 作者: 汽车电子 于 2005/6/29 18:54:00 发布:
语音变速不变调好象是“懒鸽”集团的首创 |
|
| 32楼: | >>参与讨论 |
| 作者: iQanolog 于 2005/6/29 19:29:00 发布:
事实上,我从来没有看到过“首创”的定义 创意和创造,都可以叫做首创 |
|
| 33楼: | >>参与讨论 |
| 作者: pheavecn 于 2005/6/29 21:53:00 发布:
算出频谱,再处理。 把声音分成小段,对小段进行频谱分析,在调整小段时间,合成。Ok? |
|
| 34楼: | >>参与讨论 |
| 作者: xwj 于 2005/6/30 0:22:00 发布:
pheavecn猜的很对 数字的方法基本就是这样,再加上合适的数字滤波滤去多出来的频谱就天衣无缝了 模拟的方法就是小段小段的重复,不过如果处理不好会产生多余的频谱,影响听感 由于数字方式需要进行FFT变换,所以必须要DSP才能处理 对于创新声卡自从采用EMU-10K1音频处理芯片的SB Live!以后,由于EMU-10K1芯片强劲的运算合成作基础,这些功能真的是小意思 虽然他的音质谈不上最好,但功能绝对是现阶段最好的,现在2手的SB Live!,4.1声道也就1百来元,玩玩真的不错 下面引用下介绍: 波表合成 - EMU10K1音乐合成引擎 - 512复音MIDI波表合成(硬件插值时为64复音),1024个PCI复音 - 48个MIDI通道,256音段MIDI合成,128个GM & GS兼容工具和10个工具包,1000种MIDI乐器 - 用户定制波表采样设置,包括2MB、4MB和8MB - 32MB声音样本读入主机内存,方便专业级音乐处理,不用声卡自带内存。波表库容量大的优点是声音采样真实,完美表现出各种高低效果。 效果引擎 - EMU10K1效果处理器 - 实时数字效果:反射、合唱、扩音、声音转移或变形 - 有96个硬件通道混合音频流 - 可定制架构允许自由控制声音效果和通道,用于MP3、CD播放或游戏 - 数字混音系统能够消除信号噪声 - 控制所有音源的低音和高音 3D定位环境音效 - 为四声道输出和耳机作优化,并加入HRTF(HEAD Related Transfer Function,头部关联传输功能)、Z轴/垂直方向定位,别忘了,这也是A3D 2.0的新特性之一。 - 96个DMA(Direct MEMORY Access,直接内存存取)通道,64个用于输出,32个用于效果 - 64个DirectSound二维音效通道 - 32个DirectSound3D三维音效通道 - 64个硬件波表声音 - 448个软件波表声音(必须借助CPU) - 8点采样转化 - 创新多音箱环绕声系统把声音扩展到360度,最多支持8个音箱 - 实时DSP效果 - EAX 1.0、EAX 2.0的Occlusion墙壁反射隔离、Obstruction物体阻碍声波衍射特效、EAX 3.0增强了回响效果 - 输入/输出文件式环境音效升级系统,预设值可自由定制 32位数字音频引擎 - 8位到16位声音比率 - 8KHz到48KHz采样率 - 所有音源都是32位 - 支持模拟/数字双模式 - 硬件全双工允许同时记录和回放8位标准采样率声音 - AC 97多媒体数字信号编解码器 MIDI/游戏杆接口 - 支持MPU-401 UART(Universal Asynchronous Receiver/Transmitter,通用异步接收/发送装置)模式 - 兼容数字和DirectInput游戏设备 EMULATOR IV和Darwin技术提高了声音存储时的保真度,防止了信号干扰,使音频混合采样更加准确。在声音回放方面,SB Live!没有出现嘈杂的过量高音和混浊的过量低音,保证了高音的清晰和低音的厚实。其实,声卡上的贴版式滤波电容也对声音有很大影响,这是廉价声卡所做不到的。 SoundFont是创新的波表处理技术,它不会一次性载入整个波形库,而是按需要把音色续次读入,节省了存储空间,也避免波表压缩带来的音质下降问题。CREATIVE S/W Synth是软波表自动合成,其真实度不及SB Live! MIDI Synth手动设置,如果对MIDI要求较高的朋友,就不要用自动工作啦。 在混合几个音频流时,由于它们比率的不同步,会造成回放时的声音失真。SB Live!在所有音频通道中使用8点线性插值,计算出采样点的精确数据,让波形图和原始数据相符合。如果你不能理解,请想像一下3D特效中的双线性过滤,尽管它们涉及的领域不同,不过都是为了使混和数据表现得更好的技术。 以前的声霸卡一直没有提及3D效果,因为创新有了一个更好的API(Application PROGRAMMING Interfaces,应用程序接口)--EAX(Environmental AUDIO Extensions,环境音效扩展技术)。虽然它是一个开放的技术,但只有和微软的DirectSound3D联合在一起,开发EAX游戏才会变得很容易,才能成为真正的标准。在正常情况下,游戏程序师都是用DirectSound 3D来使硬件与软件相互沟通,EAX将提供新的指令给设计人员,允许实时生成一些不同环境回声之类的特殊效果(如三面有墙房间的回声不同于完全封闭房间的回声),换言之,EAX是一种扩展集合,加强了DirectSound 3D的功能。从历史可以看到,无论一个API多么出色,缺乏开放性就会限制它的发展,3DFX Glide的消失和A3D 2.0的过渡都很好地证明了这个观点,创新当然不会走进死胡同,所以一开始已经和微软共同研发EAX。 SB Live!能够处理32个音频流,很适合Unreal等多声源游戏,毕竟世界是由各种声音组成的,仅有少量音源的环境不够真实。对于不支持EAX的DirectSound游戏和WAV、MIDI等应用,创新利用SB Live!的可定制引擎,生成假3D音效,虽然及不上实时3D定位,但也比纯粹的2D声音好多了。由于音频通道具有独立性,声音采样能够进行数字化处理,转换成所有的形式,把PC作为专业音响设备己不是梦想。 软件使用方面,安装SB Live!是PNP的,不须人工干预。值得注意的是安装之后必须在控制程序中打开四声道支持功能,否则后面两个音箱就会没声音。尽管现在的语音输入还未有重大突破,但创新还是在附送软件中提供了声音控制功能,也许无聊的时候和那个鹦鹉说说话也不错。早期的SB Live!驱动程序与Win NT不兼容,后来创新已经改善了这个问题,并把新驱动程序发http://www.sblive.com/downloads/drivers/drivers.html#drivers。除此之外,还没发现过它与软、硬件有其它不协调现象,当然我使用的是英特尔系芯片和Win98,如果你用的是VIA和Win95,还是听天由命吧。最后,请尽量选取最新版的驱动程序,在得到更多特性的同时,也能减少硬件冲突的机创新声卡的播放器 我可不是创新的,创新可没有广告费给我哦 呵呵 播放器界面: 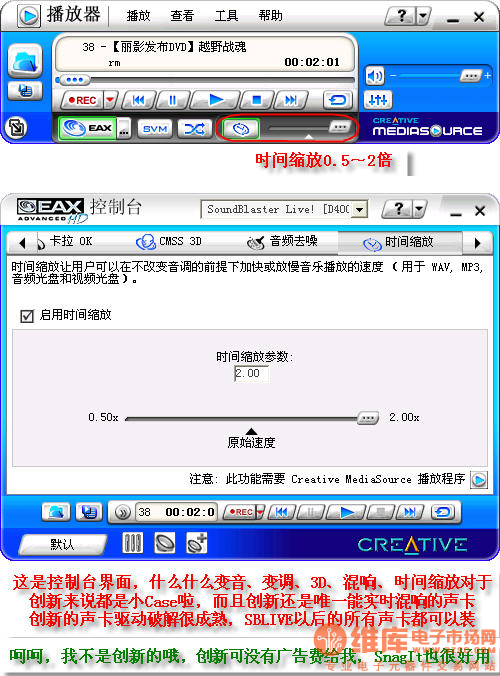 |
|
| 35楼: | >>参与讨论 |
| 作者: freego 于 2005/6/30 0:24:00 发布:
不懂MP3解码和语音知识,以下全为假设: 将定长的语音分成100US的时间片的序列,如果播放时将每个时间片都重复一遍就是慢一倍,重复两遍就是慢两倍:如果播放时将时间片每两个删除一个就是快一倍,每三个删除两个就是快两倍,以次类推。 设速度是原来的M/N,就是先将每个时间片重复N次再将每M个时间片中删除M-1个构造新的序列,再将新序列播放。 假设结束。可能听起来象鬼叫:) |
|
| 36楼: | >>参与讨论 |
| 作者: hotpower 于 2005/6/30 1:51:00 发布:
xwj帖子的界面就是漂亮 |
|
| 37楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/6/30 8:36:00 发布:
pheavecn 加上 freego 已经把基本的原理说出来了 pheavecn 加上 freego 已经把基本的原理说出来了,哪位把他们俩的整理成一条简单易懂的公式。。。。 |
|
| 38楼: | >>参与讨论 |
| 作者: busy 于 2005/6/30 9:14:00 发布:
我找了份专利文献,应该是这方面的权威资料! 大家研究研究吧!比较详细。 多谢大家答复! |
|
| 39楼: | >>参与讨论 |
| 作者: snsss 于 2005/6/30 10:50:00 发布:
看林林好久终于。找到结果了 高手都喜欢这样玩嘛? |
|
| 40楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/6/30 11:13:00 发布:
想不到楼主找到了专利的文档,哪位看不明白的请举手! 其实没看专利之前,我在10分钟内就想到如何去实现,还是用单片机来实现的。 只要是了解人声音的特性和有一点DSP经验的人闭上眼睛也能搞出来,而且会搞得很好。 今天早上我看了专利文档里面的记录,他**的把很简单的原理说得很玄!! 哪位看不明白的快举手!继续顶吧。。。。! |
|
| 41楼: | >>参与讨论 |
| 作者: busy 于 2005/6/30 11:27:00 发布:
不知道是否还有别的方法? 如果有的话就可以避开这个专利束博了! |
|
| 42楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/6/30 11:37:00 发布:
基本原理是唯一的,只是他们的专利文档上讲得太玄了, 我们还是把它踢爆好,以国内的COPY 能力,我相信市面上很快就会大量流行。。。 看不懂专利有问题请尽快举手呀。。。!继续顶。。。 |
|
| 43楼: | >>参与讨论 |
| 作者: wayner 于 2005/6/30 15:24:00 发布:
还要等一等??? |
|
| 44楼: | >>参与讨论 |
| 作者: 道源 于 2005/6/30 16:29:00 发布:
我认为本质上是音调与节拍的关系,不知对不? 不懂DSP、MP3,51懂点;玩51时,曾玩过音乐,改变节拍就可调速;大致原理我觉得是这样 |
|
| 45楼: | >>参与讨论 |
| 作者: pheavecn 于 2005/6/30 16:33:00 发布:
该专利实际上没有做频谱分析。简单的分段处理而已。谈不上保真 不知哪位知道卡拉OK设备的升降调功能是如何做的。似乎升降调也不影响速度来的。 |
|
| 46楼: | >>参与讨论 |
| 作者: chunyang 于 2005/6/30 18:40:00 发布:
确实“揭穿”算了 基本上有3种办法,其中一种是主流,算不上神秘,说清楚了,在21IC应该有大把的大小虾米可以利用合适的手段实现该功能,至于那个“专利”,确实不看也罢。 让飞船大侠别再卖关子了,快贴出极品好文。 |
|
| 47楼: | >>参与讨论 |
| 作者: xwj 于 2005/6/30 19:27:00 发布:
那个专利不看也罢,现在这种IC也很普遍了 freego的100us的时间片太短,应该设为100~300ms才比较合适,能够保留基本的频谱(不会变调) 这种方法最大的缺点就是会产生多余的频谱,影响听感,谈不上保真 最好的方法还是用DSP进行频谱分析再合成,不过成本就高多了 |
|
| 48楼: | >>参与讨论 |
| 作者: IceAge 于 2005/6/30 20:23:00 发布:
如果具有 dsp 功底,不难 以某一 sampling rate 转换为数字,做 fft,以不同的速率做逆变换即可。 或是将 fft 序列转换为不同下频率的序列,用相同的速率做逆变换 例如: 44K sampling rate, 4096点 ---> FFT --> 2048 个复数序列 --->变换(有专门的算法, 最简单的可用线性插值) ---> 1024 个复数序列 ----> IFFT ---> 44K sampling rate, 2048点--->DAC 这样速度增加一倍 |
|
| 49楼: | >>参与讨论 |
| 作者: 潜艇8421 于 2005/7/1 8:27:00 发布:
楼上说的太玄了吧,不要把我等菜鸟唬破了胆呀, 事情看来越来越抽象了,楼上的是博士学位毕业的吧,化形象为抽象是中国的一大特色,楼上‘牛’呀。。。。! |
|
| 50楼: | >>参与讨论 |
| 作者: zhousd 于 2005/7/1 8:54:00 发布:
有趣的化形象为抽象,俺看得明白,看来俺已达到博士了? 不过俺还是不得要领,看来这道题就算是博士也搞不定! 哪位是小学水平的请进来发表一下! |
|
| 51楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/1 9:08:00 发布:
RE chunyang 其实这里很多大虾早就知道该如何去做了, 只是他们太谦虚而已,希望有人能用楼上所说的小学水平就能说明白的原理来。 但是我的看法是没有‘中专’或‘高中’以上的水平是没法给他禅明的!大家可别笑,我可是说真的! |
|
| 52楼: | >>参与讨论 |
| 作者: rivflood 于 2005/7/1 10:05:00 发布:
在网上搜了一下 bbs地址 http://bbs.fudan.edu.cn/cgi-bin/bbs/bbscon?b=EE&f=M.1114435317.4960&n=1776 其中有讲到 ☆──────────────────────────────────────☆ willywu (等待戈多) 于 2005年04月24日16:56:49 星期天 提到: 我觉得一个办法,是把音乐分成小块,比如每一块一秒钟,然后一秒钟播放两次。当然这 样肯定会有问题,但是如果不是一秒钟,而是0.01秒,是不适就有效过了呢?猜想而已。 : 有人知道吗?谢谢。 ☆──────────────────────────────────────☆ anti (等待馅饼) 于 2005年04月24日22:59:16 星期天 提到: 人耳只对频率的幅度敏感,对频率的相位并不敏感。所以实际上的作法 和你猜想的差不多。 具体作法是用短时傅立叶变换,把10ms左右的声音信号转换到频域 上,然后保持各频率上的幅度值不变,用其综合出20ms左右的时域 信号出来。这样综合出来的声音,其相位信息是错误的,但人耳分辨 不出;声音放慢了一倍,但频率却不变。 : 我觉得一个办法,是把音乐分成小块,比如每一块一秒钟,然后一秒钟播放两次。当然这 : 样肯定会有问题,但是如果不是一秒钟,而是0.01秒,是不适就有效过了呢?猜想而已。 : : : 有人知道吗?谢谢。 --------------------------------- 以上信息转贴 --------------------------------- 我想简单的做法就是在把音频分成小段,要慢速播放的时候就讲相邻的段重复播放,减速的时候将相邻的段落删除,就如同一个较长的正弦波删除几个周波,在时域上还是正弦波,周期不变。当然这样做会损失掉或者增加一些频谱成分,就如同 xwj 所说,好一些的做法就要用DSP进行频谱分析再合成,具体原理如同 IceAge 所说 * - 本贴最后修改时间:2005-7-1 10:07:20 修改者:rivflood |
|
| 53楼: | >>参与讨论 |
| 作者: cxc51 于 2005/7/1 10:45:00 发布:
啊,我也来了 学习学习 |
|
| 54楼: | >>参与讨论 |
| 作者: busy 于 2005/7/1 12:06:00 发布:
的确,用删除小段(快播)、重复小段(慢播)可以实现 声音的变速不变调,可是正如很多网友想的,这样子是不能够实现声音的高保真的,只能够用频谱方法处理才能做到高保真,不过这方法太复杂了啊!至少要具备相关的理论知识!不能普遍使用。 |
|
| 55楼: | >>参与讨论 |
| 作者: IceAge 于 2005/7/1 21:09:00 发布:
用时域的方法不会比频域更简单 而且正像 busy 所说, 不能够或是极难实现声音的高保真。其实 fft 并没有多难,尤其是应用。我把上面提到的方法解释的再清楚些: 44K, 4096点: 时间片 4096/44 = 93 ms ,基波频率:44K/4096 = 10.74Hz FFT 后得复数数组: R[2048] + j I[2048],其中: R[0] + jI[0] 为DC, 幅值为 sqrt(R*R + I*I) R[1] + jI[1] 为10.74Hz, 幅值为 sqrt(R*R + I*I), 相位 arctan(R, I) R[2] + jI[2] 为 2* 10.74Hz R[3] + jI[3] 为 3* 10.74Hz 以此类推。 变换到r[N] + j i[N]: 有专用算法, 也可用线性插值。比如N =1024 则基波频率:44K/(2N) = 2 * 10.74Hz r[0] + j i[0] = R[0] + j I[0] r[1] + j i[1] = R[2] + j I[2] r[2] + j i[2] = R[4] + j I[4] r[n] + j i[n] = R[2n] + j I[2n] 保持频率不变! r[N] + j i[N] 做 FFT 逆变换得 2N 点: 时间片 2N/44K , 对于N =1024, 则为 46.5 ms 这样93 ms 的数据被转换为 46.5 ms 而不变调。 |
|
| 56楼: | >>参与讨论 |
| 作者: IceAge 于 2005/7/1 21:40:00 发布:
同理,要实现 karaok 的变调不变速 只需将 R[2048] + j I[2048] 数组中的数据上下搬动,即左移或右移频谱, 再转回到时域即可 |
|
| 57楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/2 8:31:00 发布:
领教了楼上很高深的算法,有一个问题请教, 我对视频上的压缩倒有研究,但是对FFT 处理声音不是很精通, 请问楼上的前辈,R[1] + jI[1] 为10.74Hz, 如果这个数据频率固定了对要求的声音处理会有意义吗? |
|
| 58楼: | >>参与讨论 |
| 作者: busy 于 2005/7/2 8:57:00 发布:
顶!谢谢IceAge兄的详细解答! 前面阔然开朗...... |
|
| 59楼: | >>参与讨论 |
| 作者: sunshine98 于 2005/7/2 9:00:00 发布:
lol,,,hot ! continue... |
|
| 60楼: | >>参与讨论 |
| 作者: pheavecn 于 2005/7/2 9:05:00 发布:
本贴 可能是本年度21ic技术含金量最高的帖子。 期待后续... |
|
| 61楼: | >>参与讨论 |
| 作者: chunyang 于 2005/7/2 11:23:00 发布:
哈哈,第2种和第3种方法已基本明朗了 相对而言,第一种方法几乎没有实用意义,但也是一个时代的产物,我就说说这第1种方法和关于声音的有关基础理论吧。 人说话、唱歌时发出的声波很复杂,从频域上看是由基波和成分丰富的谐波组成。音调的高低,主要由基波的频率决定,音色则由谐波决定,还有个要素声音的强度,他们共同构成了声音的独特性。 音调的高低,现在主要用8度表示法来标定,然后用12平均率将每个8度分成12个等距半音,大家看看钢琴键盘,1个8度由7个白键和5个黑键组成,正是据此而成,相邻8度间的同唱名音符频率相差正好1倍。 既然音调主要由基波成分的频率来决定,那么想办法改变基波的频率即可改变声音的音调。在模拟时代,这就是“变调”的理论基础。当年(1990年前后)有一颗专用芯片(抱歉,年代久远,具体型号已忘),可将音程升高或降低8度,它的工作原理是滤波器+PLL,降8度时,它工作在2分频状态,升8度时,它工作在2倍频状态。我曾用它指导我弟弟做了一台带混响及可变调的卡拉OK机,不过该芯片的效果很烂,降8度如女声变男声还行,升8度听起来则像“外星人”,所以用它配合磁带变速来实现“变速不变调”的话,疯狂李扬会变成C3PO,而且它最大的问题是只能简单地按2的倍数来变频升降调,应用就十分有限了,不过用于电话变声整蛊的话,还是个不错的选择。 “变速不变调”的实质其实是变调技术,但要取得好的效果还是非常有“讲究”的。最后“总结”一下3种变调的方法,以邀坛子里的大侠高人出帖明示。 第1种:模拟变频法。俺老汉先献丑了。 第2种:时域法,现在复读机等廉价产品用的“变速不变调”即基于此方法。期待某某大侠高招出手给大家详解。 第3种:频域法,高级数字音频处理设备均用此法,理论虽不算很难,但涉及复杂的算法,有关工艺处理良好的话,可实现高保真。期待某某博士高谈宏论给大家指点迷津。 |
|
| 62楼: | >>参与讨论 |
| 作者: kam 于 2005/7/2 12:54:00 发布:
顶!chunyang的分析是另一翻天地! 一下子看了全部帖子,加深理解了! 都期待着高人的详解出现!当然有具体的算法就更让人醒神了! 希望在这样的“时世”下造个英雄出来! |
|
| 63楼: | >>参与讨论 |
| 作者: 潜艇8421 于 2005/7/3 23:02:00 发布:
人气太旺,这么快就沉了!顶 |
|
| 64楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/4 8:36:00 发布:
chunyang 前辈已讲出声音的基本原理,讲很很好, 有了声学上的基本原理,接下来请大家先思考一个问题: 一N个周期的频率固定的正弦波,如何减去M个周期而不失真?(M<N) 大家能否用一条很简单的数学表达式总结出来,看看自已总结的是否跟专利上说的一样? * - 本贴最后修改时间:2005-7-4 8:37:48 修改者:宇宙飞船 |
|
| 65楼: | >>参与讨论 |
| 作者: gcl4u 于 2005/7/4 11:09:00 发布:
试试分析一下先! 声调的变化是频率变化引起的,故不变调是要保持声音信号的频率不变。 变速的原理是什么我也说不好,估计是将声音信号的频率保持不变的基础上将信号延长了,这样每一个发音的长度加长,是不是速度就慢呀?另外,在信号间加间隔是不是可取?这样发音间会有停顿,听起来会不舒服! |
|
| 66楼: | >>参与讨论 |
| 作者: wsj0902 于 2005/7/4 12:36:00 发布:
都是些高人,俺也去搬个凳子在旁凑凑...... |
|
| 67楼: | >>参与讨论 |
| 作者: pheavecn 于 2005/7/4 18:39:00 发布:
加把煤,洗耳恭听。 |
|
| 68楼: | >>参与讨论 |
| 作者: d1276 于 2005/7/4 21:06:00 发布:
哈哈哈,这么多人灌水啊,别买关子了,俺不想了解了 |
|
| 69楼: | >>参与讨论 |
| 作者: violit 于 2005/7/5 0:12:00 发布:
本贴的技术含量还真的可以 不过阿Q的精神也是得到了淋漓尽致的体现 话也说过来了,这是没有办法得,哪一个习惯了仰望别人的人不奢望被别人仰望呢?就让着用帖子砌成的高台承载某些人的荣耀吧。 同时提醒大家尊重专利权人的权利,虽然现在可以用简单的单片机实现这个效果,但是哪位能在95年就实现或者发现?即使能够,又有哪位有这个头脑和魄力去申请专利呢?请不要单薄的鄙视别人的专利(技术研讨除外),即使这个技术在今天看起来也不是什么高明的东西,毕竟他还含有前瞻性的观察和魄力。 * - 本贴最后修改时间:2005-7-5 0:22:13 修改者:violit |
|
| 70楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/5 9:00:00 发布:
我说楼上的,在我没看专利文档之前仅仅是思考了10分钟 就把原理想好了,后来贴主说有专利文档,我下载之后看了竟然和自已想的不谋而合,难道这也算侵权?? 这个贴子如果要用FFT 来讲明基本原理,末免太看得起读博士的朋友了!中国就是这样,很简单的原理为何一定要用到高深的理论来说明?把一些有很强动手能力的人都挡在门外? 知道基本原理我想很多人都能够不费吹灰之力就写好程序! 何来阿Q精神,我只是想一步一步引领没有数学基础的朋友思考这个问题,难道我写出来是比高手看的?如果不能大众化明了,写出来有何意义? |
|
| 71楼: | >>参与讨论 |
| 作者: chunyang 于 2005/7/5 9:26:00 发布:
方法是有差异的 95年的那个专利,其实其原理PHILIPS早在70年代末与SONY共同制订CD标准的时候就已经确立了,只是实现手段及效果还是各有差异的,正是如此,此专利反复多次申请后才获批,而且尚未见到权利人有任何直接的产品出台,只是见其在打官司,其实只要检索一下95年前的国外文献,只要回避其“工艺”方面的权利要求项(我未看其权利要求书,不敢确定是否有该方面内容)即可以以公知技术为由诉其专利无效或不构成“侵权”,公知或已公布的数学原理是不能成为专利的,而且人家多年前就已经公布了,有关学术论文更是多不胜收。95年前,我已经见识了日本雅马哈(90年代初,硬件系统)和新加坡创新(95年,PC平台软件)的专业变调产品。 善于学习的人首先要有正确的学习态度,有人大卖“关子”那我们就洗耳恭听,期待精彩,如果届时没有什么有价值的内容,再行攻击指责才名正言顺。 来,再次呼吁大侠及博士一展精彩! |
|
| 72楼: | >>参与讨论 |
| 作者: stintair 于 2005/7/5 11:01:00 发布:
把问题放在高保真上面吧。 实现变速不变调,我觉得最主要还是做到到高保真,这才是技术的核心。否则,意思不大。期待本贴能够讨论出一种合理的技术方案,使大家共同提高。 主要有以下几个核心问题需要阐明: 1.人耳对声音的感知原理。 2.何为变速不变调(本人觉得应该是功率谱不变,即各个频率成分的功率不变)。 3.采用何种算法可以实现。 4.硬件实现。 望各位大侠积极讨论 * - 本贴最后修改时间:2005-7-5 11:02:49 修改者:stintair |
|
| 73楼: | >>参与讨论 |
| 作者: Herowa 于 2005/7/5 13:00:00 发布:
我也想知道 我不做音频的,不过已经被这个帖子深深吸引了,等待高人道破天机! |
|
| 74楼: | >>参与讨论 |
| 作者: elleman 于 2005/7/5 13:12:00 发布:
插值算法吧! 插值算法吧!具体下来有线性,非线性,都是基本的数学知识。不知对否? |
|
| 75楼: | >>参与讨论 |
| 作者: stintair 于 2005/7/5 13:48:00 发布:
音调,音量,音色 音调:音调高低是按照音阶来变化,是用声波的频率高低来定量听者的感觉, 频率高则音调高;频率低则音调就低。 音量:音量是指声音的大小和强弱。 音色:音色就是指声音所包含的谐波频率(泛音)成分。 |
|
| 76楼: | >>参与讨论 |
| 作者: stintair 于 2005/7/5 13:57:00 发布:
纠正楼上的楼上的楼上……的一个错误,分析声音信号不能采用FFT FFT只能处理定常问题,如一个函数对其进行傅立叶展开,可以得到各频率成分。 但是,声音信号应该是一个随机信号,其中包含了各种频率成分,并且,各频率成分是时变的,因此才会产生音调的变化,所以,对其做FFT是没有意义的,声音信号的分析必须采用功率谱分析的方法,或者用STFT短时傅立叶变换。 * - 本贴最后修改时间:2005-7-5 14:47:15 修改者:stintair |
|
| 77楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/5 14:24:00 发布:
楼上可否跟大家用功率谱来分析一下? 我还没领悟到这种分析大法,原闻其详,洗耳恭听教诲! |
|
| 78楼: | >>参与讨论 |
| 作者: 潜艇8421 于 2005/7/5 14:30:00 发布:
八仙过海,各显神通,热闹极了,搬长椅子睡着听! |
|
| 79楼: | >>参与讨论 |
| 作者: stintair 于 2005/7/5 14:43:00 发布:
没听说过可以看看数字信号处理的书 几乎每本书上都有,这又不是什么新的技术,几十年前就有了。我新来的,贴不了图,没办法贴公式啊。呵呵。你用GOOGLE检索一下吧。 * - 本贴最后修改时间:2005-7-5 14:50:00 修改者:stintair |
|
| 80楼: | >>参与讨论 |
| 作者: stintair 于 2005/7/5 15:04:00 发布:
这些都是数字信号处理的东东 其实这个东西理论上研究的已经比较成熟了。但毕竟这是另外一个学科的内容,单懂单片机是很难搞这个滴,有空多学点儿其他学科是有帮助滴,呵呵。在这里大家讨论讨论,共同提高吧。重新提一下重点:实现Hi-Fi. 版里那个博士生呢,出来表个态。 |
|
| 81楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/5 17:45:00 发布:
那个博士的要求很高,楼上还是先讲点FFT来吊下大家胃口吧! |
|
| 82楼: | >>参与讨论 |
| 作者: IceAge 于 2005/7/5 20:49:00 发布:
stintair 说的有一定的道理,不过"分析声音信号不能采用FFT" 不敢苟同。因为我们处理的是一段信号,即使使用功率谱,也必须使用前一段(一个周期)的数据。尽管数据是随机的,频率是时变的,重要的事,fft可以得到一段数据的频谱。例如 44K,4069点,可以得到 DC,2047条正玄波(频率 n*10.74 Hz, 幅值为 sqrt(R*R+I*I), 相位 arctan(R, I)), 当我们生成这 2048 条 93 ms 的曲线并叠加在一起的时候,我们又得到了原来的曲线。或许信号频率不在 n*10.74 上,但这 2048 条曲线足以将其拟合出来。 |
|
| 83楼: | >>参与讨论 |
| 作者: pheavecn 于 2005/7/5 23:06:00 发布:
越来越精彩了!!! 很佩服各位高手的理论功底。 |
|
| 84楼: | >>参与讨论 |
| 作者: busy 于 2005/7/6 12:52:00 发布:
高手真多! 增长了见识! 不知道那位高高手大虾能否整理个标准的、详尽的答案出来呢?最好能结合一些代码或者流程图讲解就非常的VERY GOOD! 不知道“飞船兄”是否能给我们大家露一手? 期待ING........ |
|
| 85楼: | >>参与讨论 |
| 作者: djha 于 2005/7/6 15:02:00 发布:
搬个椅子坐着听! |
|
| 86楼: | >>参与讨论 |
| 作者: stintair 于 2005/7/6 15:43:00 发布:
因为时间较短,所以拟合效果较好 其实你采用的就是短时傅立叶变换的原理。短时傅立叶变换是采用加窗的办法,让窗的长度足够小,那么在窗内的一段数据就可以看成是相对稳定的信号,因此可以对其进行FFT。但是如果数据过长,那么相对稳定的假设就不成立了,因此就不能直接采用FFT,不信你把93ms变成93s,肯定不行。即使用功率谱分析的办法,也需要加窗。 |
|
| 87楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/6 19:34:00 发布:
给点提示:跟2*3.14 有关的概念 |
|
| 88楼: | >>参与讨论 |
| 作者: water2005 于 2005/7/6 20:21:00 发布:
顶飞船! 快把你的理论说出来听听! |
|
| 89楼: | >>参与讨论 |
| 作者: IceAge 于 2005/7/6 21:04:00 发布:
stintair兄此言差矣 时间窗加长时,意味着减少了基波频率,增加了解析度。如93 ms 变为 93 s, 那么fft 点数为 4096000, 基波频率=44K/4096000 = 0.0107421875Hz ,即频谱的分辨率为0.0107421875Hz,换句话说,由 2048000 条dc+正玄波来拟合这 93s的波形,即做fft逆变换时,可由2048000 个复数重构原来93s的波形。 这就是时域与频域的区别。时域信号是时变的,而fourier 是积分变换,与时间无关,呵呵,这个概念是有点难以理解。不过只要记住是可逆的,就行了 再回到变调问题上:假设 A 是原始波形,B 是理想的不变调波形,a, b为fft后的频谱,a, b 可逆变换回 A, B. 那么我们只要找出a, b 的关系即可。按我的理解(我没做过声音的处理),a, b 的形状应该是一样的,直接变换即可。或者是左移,右移频谱,先实现变调,然后改变速度来实现变速不变调 整个变换为: A--> a ---> b ---> B |
|
| 90楼: | >>参与讨论 |
| 作者: maorukun 于 2005/7/6 22:20:00 发布:
恩 速度的改变表示为x(An) 令An=n’,有新的频域为 ,相当是频域的取样间隔增大。数字语音本来就是频域抽样,进行处理(如FFT);只要采样时N值购大,这是不会改变频域特性的。 最终做到语速变化(A大于1则加快,小于1则变慢),而语调不变(频域)。 |
|
| 91楼: | >>参与讨论 |
| 作者: linwei1234 于 2005/7/6 22:32:00 发布:
我觉得这个东东原理很简单! 我觉得这个东东原理很简单! 并非快放就是要把所有音频全部播放! 我认为是切掉其中的! 即按常速跳播就行了! |
|
| 92楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/6 22:47:00 发布:
终于见到一个PASS 之人!楼上不错,有悟性! 不过我还是想听听老前辈们高深的FFT处理方法,好玄呀。。。。! |
|
| 93楼: | >>参与讨论 |
| 作者: flymonkey 于 2005/7/6 23:26:00 发布:
这有何难? 延时就在声音中每隔一段(如一ms),插一段前面的取样到频率的信号,这样调子不会变,但时间延长了,或许更本不取样,直接插入一段空白,对声音没影响,实现成本非常低廉,甚至不用单片机,只要几毛钱! 减时相反! |
|
| 94楼: | >>参与讨论 |
| 作者: YuanChong 于 2005/7/6 23:34:00 发布:
我想应为移频 |
|
| 95楼: | >>参与讨论 |
| 作者: flymonkey 于 2005/7/6 23:48:00 发布:
移频是不行的! 假如声音是500hz~10000hz,慢放成200hz~4000hz,移频后如果要低端不失真,那么应该就变成500hz~(4000hz+200hz),结果还是变调了! |
|
| 96楼: | >>参与讨论 |
| 作者: flymonkey 于 2005/7/6 23:49:00 发布:
上面有误 上面有误 应该是500hz~(4000hz+300hz) |
|
| 97楼: | >>参与讨论 |
| 作者: lfjwfm 于 2005/7/7 0:25:00 发布:
我也想知道ing |
|
| 98楼: | >>参与讨论 |
| 作者: IceAge 于 2005/7/7 0:43:00 发布:
粗略看了一下专利。看来发明者对声音作了深入的研究 基于音元的时域方法实现起来确实简单,一单片机足矣。对于语音这种音元明显的单音信号,的确管用。 个人认为,用 dsp 实现并不难,没什么挑战性,毕竟现在fft, ifft 等等算法遍地都有,matlab/simulink 上的例子估计比比皆是。而时域的方法实现是一个挑战,仅仅通过删除或添加某些点便能达到效果,确实很神奇。 期待着飞船大侠的高论。 |
|
| 99楼: | >>参与讨论 |
| 作者: IceAge 于 2005/7/7 0:52:00 发布:
To: flymonkey 一般频谱频率使用的是 log , 所以 200 hz 移到 500hz 时,相应的 4000hz 移到了 10000, 而不是 4000+300 |
|
| 100楼: | >>参与讨论 |
| 作者: stintair 于 2005/7/7 9:47:00 发布:
IceAge兄好像理解有误 IceAge兄的说法好像是有误的: 正因为傅立叶变换是一个积分变换,因此,它反映的是一段信号在积分域当中的统计特性。为了说明这点,我举个简单的例子:比如我在1s-2s时频率为100hz,在2-3s是频率为150hz,其他时候频率为1000hz,总采样时间为90s,这样的一个简单信号,经过傅立叶变换以后,得到的是一个频谱图,并且在100hz,150hz,1000hz处出现峰值。并且前两个峰值应该随着采样时间增长而降低。对于这种简单的情况直接用FFT就是不合适的,因为无法将其还原到时域,保证100hz,150hz,1000hz出现在指定的位置,得到的只是几个正弦波在时域范围内的叠加,这肯定是不对的。问题的原因就在于没有考虑频率变化所对应的频率变化。相反,对于上述信号,如果每秒分析一次,就完全可以复原信号。所以必须加窗,并且窗不能过大。对否? |
|
| 101楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/7 9:47:00 发布:
linwei1234 都说中了,能否出来跟大家总结一下! linwei1234 发表于 2005-7-6 22:32 侃单片机 ←返回版面 我觉得这个东东原理很简单! 我觉得这个东东原理很简单! 并非快放就是要把所有音频全部播放! 我认为是切掉其中的! 即按常速跳播就行了! //--------------------------- 他都说中了,致于如何‘切掉’同‘跳播’这个动作,哪位大侠理解的请站出来解译一下! |
|
| 102楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/7 9:53:00 发布:
再提示一遍2Л的概念 宇宙飞船 发表于 2005-7-6 19:34 侃单片机 ←返回版面 给点提示:跟2*3.14 有关的概念 |
|
| 103楼: | >>参与讨论 |
| 作者: YuanChong 于 2005/7/7 11:48:00 发布:
其实用goldwave模拟一下就知道 用goldwave将待编辑的声音分成足够多份,铁道兵然后把1,3,5...或2,4,6... 剪出,再拼在一起,声音快了而音调不变。 |
|
| 104楼: | >>参与讨论 |
| 作者: 方林 于 2005/7/7 12:01:00 发布:
次品 出现这种情况的最大可能就是你所买的复读机属于次品货! |
|
| 105楼: | >>参与讨论 |
| 作者: IceAge 于 2005/7/7 12:46:00 发布:
linwei1234老兄还是没有完全理解 我明白老兄的意思。老兄所提出的情况,实际上如果你做一fft,看看频谱,你就会明白,很多其他的频点上也有突起,即这段波形也包含了其他频率。浅显一点:1s时频率为100hz, 在2s是频率为150hz,这前1s 中的150hz与后1s 中的100hz 信号会被无数的其他正弦波抵消。想想正弦波如何合成方波的经典例子 那个专利已经把原理讲的非常透彻了,不论水平高低,至少是进行了深入的研究 |
|
| 106楼: | >>参与讨论 |
| 作者: stintair 于 2005/7/7 12:50:00 发布:
呵呵 * - 本贴最后修改时间:2005-7-7 12:54:09 修改者:stintair |
|
| 107楼: | >>参与讨论 |
| 作者: spadeace 于 2005/7/7 13:23:00 发布:
核心提示 抽样间距... |
|
| 108楼: | >>参与讨论 |
| 作者: stintair 于 2005/7/7 13:27:00 发布:
快要得出答案了,IceAge老兄 时频要对应啊。直接采用FFT无法给出信号频谱随时间变化的规律,这一点毫无疑问。 整个流程应该如此: 对数据进行加窗,窗的宽度为时间T,对窗内的数据FFT,得到频谱,然后iFFT到T1长时间上,即:提取T内的频率值,在T1内用正弦波代替,移动窗到下一个位置,重复上述过程知道处理完毕所有数据。思想就是分段分析,分段拟合。 如T>T1则总时间变短,声音速度提高,反之速度降低。 这也同时说明了,为什么直接添加数据点,或者删除数据点也能达到相似的效果:取一小段数据,如果够短,其频谱相对简单,所以可以直接将其复制到与其相邻位置那么可以认为其频谱不变,时间增倍。反之亦然。但是,这种方法没有经过差值运算,只是静态拷贝缺少平滑和过渡,这会导致音色降低,因此HIFI恐难保证。 |
|
| 109楼: | >>参与讨论 |
| 作者: jy6715 于 2005/7/7 13:46:00 发布:
顶 |
|
| 110楼: | >>参与讨论 |
| 作者: ccri898 于 2005/7/7 15:28:00 发布:
长见识了! |
|
| 111楼: | >>参与讨论 |
| 作者: YuanChong 于 2005/7/7 15:49:00 发布:
2*2.14说了等于的白说 2*3.14 |
|
| 112楼: | >>参与讨论 |
| 作者: zhiyunli 于 2005/7/7 16:51:00 发布:
想要演示程序的留个邮箱,最好是163的 我给楼主发过了,写得比较详细,另外还附上了PC程序和示例文件,有兴趣的可以先体验一下。 |
|
| 113楼: | >>参与讨论 |
| 作者: busy 于 2005/7/7 17:47:00 发布:
zhiyunli的演示程序果然强! |
|
| 114楼: | >>参与讨论 |
| 作者: IceAge 于 2005/7/7 21:12:00 发布:
stintair老兄,fft没必要再争论了。建议你用 matlab 之类的工具作个实验你就会明白的。我以前也有和你一样的困惑。 再长的一段波形,即便是1小时,<b>一定</b>能用 n 条正弦波拟合出来。仔细看看连续 fourier 变换和逆变换的公式,认真想想为何与时间无关。 关于 fft 的争论就到此为止吧。 时域的方法很清楚,因为专利已讲的很明白了。这种方法好处是简单,缺点是可靠性差(这是使用过零检测的通病),针对语音等有效,通用性不强。 数字算法的最大缺点就是对cpu, ram 等的消耗,优点是显而易见的。 |
|
| 115楼: | >>参与讨论 |
| 作者: busy 于 2005/7/8 11:16:00 发布:
哈哈,个个都是高人,21IC果然是卧虎藏龙的地方 总算是看到了“八仙过海,各显神通了”。 |
|
| 116楼: | >>参与讨论 |
| 作者: iQanalog 于 2005/7/8 22:38:00 发布:
搞来搞去就了了以chunyang为核心了 为了表示对他的支持,偶把刚才的的一个回帖灌到这来:这个问题的处理,频谱应当是关键。决不象音阶变调那么容易。 ____________________ 你说的是谐波,不是音阶,更不是和弦。 和弦一般是在基频及其2倍之间,当然,复杂和弦也有高一些的。 如按12平均律划分的半音音阶,1 3 5是大三和弦,其中5音(五度音)的频率约是1音有3/2倍(纯律或五度相生律是准确的3/2倍),其数学表达式是:2 的7次方再开12次方倍。 这个数在单片机是无法准确实现的,一般采用一定的分数来表示,如3/2等,意思是将一个3倍频的声音进行2分频就能得到1.5倍频,也就是suo音(纯五度音)。当对这个音进行不同的频谱处理时,就可以得到不同音色的声音,如模拟钢琴音、提琴音、小号音....在要同时进行音色处理时,单片机实现和弦,有一定的困难,一般地,能较好地实现基音,音色处理由外围电路实现为好,---我没做过,但我是这样想的,希望你能突破。 多律制音阶可以用单片机实现,不过,原理上我认为用外围电路配合最好。起码电路设计阶段相对简单----本人一般不希望这种事一步到位,多希望有给研究完善的机会。。。。。 _____________________________________________________ 12平均律是几何平均,级数关系如下: 2 的0次方再开12次方倍----基音-----------duo 2 的1次方再开12次方倍----半音,小二度--- 2 的2次方再开12次方倍----大二度---------re 2 的3次方再开12次方倍----小三度--------- 2 的4次方再开12次方倍----大小三度-------mi 2 的5次方再开12次方倍----纯四度---------fa 2 的6次方再开12次方倍----大四度--------- 2 的7次方再开12次方倍----纯五度---------suo 2 的8次方再开12次方倍----小六度--------- 2 的9次方再开12次方倍----6度------------la 2 的10次方再开12次方倍---小7度---------- 2 的11次方再开12次方倍---7度------------si 2 的12次方再开12次方倍---二倍频:8度----duo 高8度 |
|
| 117楼: | >>参与讨论 |
| 作者: zhousd 于 2005/7/8 23:20:00 发布:
出差两天,热闹非凡!继续等待多些高人。。。。 哪位是高人的请再露一手,轮到我出马时就再没有机会露的了! 末露的请尽快!机不可失。。。! 呵呵! |
|
| 118楼: | >>参与讨论 |
| 作者: YuanChong 于 2005/7/9 12:02:00 发布:
为什么还不见宇宙飞船出来? |
|
| 119楼: | >>参与讨论 |
| 作者: kanprin 于 2005/7/11 16:01:00 发布:
晕过去了!半个世纪还得不到答案! 果然是高人风范!尤抱琵琶还遮面!千呼万唤死出来啊! |
|
| 120楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/11 19:30:00 发布:
楼上的说话太难听了!不打算看迷底了? |
|
| 121楼: | >>参与讨论 |
| 作者: njust726 于 2005/7/11 22:10:00 发布:
越来越复杂 也说下自己的看法:变快速大概就是抽取,前面加个抗混叠滤波;慢速大概就是插值,后面加个抗镜像滤波;也可以两个同时加上处理,做非整数倍变速。 不是很懂,期待早点见到谜底。 |
|
| 122楼: | >>参与讨论 |
| 作者: IceAge 于 2005/7/11 23:06:00 发布:
呵呵,怎么还有人不知道原理。 把 Busy 兄弟找到的专利连接在贴一次: http://file.21ic.com.cn/变速不变调的专利文献.rar 要点:通过 过零 计算出基波的周期,通过峰值比较可以得到“音元“的周期。 删除/添加 数据的方法很多,最简单应该是移动平均法,例如:3 个周期变为2个,只要将1和2周期的点相加除2, 2和3的点相加除2,即可。增加点同理 时域法与频域法的基本原理相似,只是时域仅使用了过零点和峰值的信息,而fft 法则使用了所有数据点的信息,因而效果好但计算量大 |
|
| 123楼: | >>参与讨论 |
| 作者: pheavecn 于 2005/7/12 7:31:00 发布:
帮各位高手和期待谜底的众人砸kanprin一砖头。 不要影响我们看谜底。 |
|
| 124楼: | >>参与讨论 |
| 作者: kanprin 于 2005/7/12 8:18:00 发布:
呵呵, 不要砸,那个字打错了,是千呼万唤始出来!! 大虾们不要介意,我在此严肃道歉! 期待结果!! |
|
| 125楼: | >>参与讨论 |
| 作者: agnd 于 2005/7/12 9:25:00 发布:
真是一帮书痴 这是别人利用你自己的听觉神经和大脑对声音的经验处理来骗你的,你却听不出来,让自己的耳朵被别人利用欺骗自己 |
|
| 126楼: | >>参与讨论 |
| 作者: xwj 于 2005/7/12 9:49:00 发布:
呵呵,要我砸我就砸飞船,卖关子也有个度 难道非要千呼万唤Si才出来? |
|
| 127楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/12 9:55:00 发布:
IceAge 全说了,好象已到尾声了,哪位对他的说 话不明白的请举手发问呀! |
|
| 128楼: | >>参与讨论 |
| 作者: dm641 于 2005/7/12 10:00:00 发布:
佩服死你了,宇宙飞船! 你已经将我的“偶像”:芙蓉姐姐挤到了第二位! 从本贴开始,你字字"珠玑",可就是不说答案! 几位水平高的,也被你攻击。 大家是来学东西的,不是来看卖关子的,更不是来学卖关子的! 知道就说,不知道就听人说 服了! |
|
| 129楼: | >>参与讨论 |
| 作者: YuanChong 于 2005/7/12 11:18:00 发布:
dm641r的话,我有同感! |
|
| 130楼: | >>参与讨论 |
| 作者: iQanalog 于 2005/7/12 19:17:00 发布:
会不会成为钓鱼工程? |
|
| 131楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/12 23:37:00 发布:
看来不说不行,也不得不吹了!秘密大揭破!GAME OVER! 每个人音调的高低反应在电子专业术语就是频率的高低,声音除了基频之外还有丰富的N次谐波,能量最大的当然是基频了。 提速或减速的秘密就是: 要保持音调不变,也就是使频率保持不变,资料的删除或叠加必需在每个周期内的同一相位作删除或叠加。 举个提速的例子: 在初相位是30度定了一个资料点,那么就要找到每隔(360*N)+30的位置的数据用作提前读出的数据。其中(360*N)其中的N代表的是频率的周期,当N=1 时声音快一倍,N=2 时快2 倍 N=i 时就是i 倍。 基频和谐波确定实际很容易,把数据放在内存里找极值,次极值,二次极值,N次极值就能确定基频和谐波,用单片机来实现是很容易的。 最后在此提下FFT的原理: FFT变换实质上是做了个固定而且已知的频率表,最终还是要用程序判极值,FFT变换处理在此实在是多此一举,画蛇添足。 * - 本贴最后修改时间:2005-7-12 23:47:17 修改者:宇宙飞船 |
|
| 132楼: | >>参与讨论 |
| 作者: iQanolog 于 2005/7/13 1:00:00 发布:
先说一点:GAME OVER!? 看来不说不行,也不得不吹了!秘密大揭破!GAME OVER! 宇宙飞船 发表于 2005-7-12 23:37 侃单片机 ←返回版面 举报该贴 每个人音调的高低反应在电子专业术语就是频率的高低,声音除了基频之外还有丰富的N次谐波,能量最大的当然是基频了。 >>最少这句有问题:好象长笛的频谱(反正是一种乐器,如果没有记准,纠正即是,别抛砖啊!),就不是这样。 哈哈,飞船你别想得太容易了。。。。。 提速或减速的秘密就是: 要保持音调不变,也就是使频率保持不变,资料的删除或叠加必需在每个周期内的同一相位作删除或叠加。 举个提速的例子: 在初相位是30度定了一个资料点,那么就要找到每隔(360*N)+30的位置的数据用作提前读出的数据。其中(360*N)其中的N代表的是频率的周期,当N=1 时声音快一倍,N=2 时快2 倍 N=i 时就是i 倍。 基频和谐波确定实际很容易,把数据放在内存里找极值,次极值,二次极值,N次极值就能确定基频和谐波,用单片机来实现是很容易的。 最后在此提下FFT的原理: FFT变换实质上是做了个固定而且已知的频率表,最终还是要用程序判极值,FFT变换处理在此实在是多此一举,画蛇添足。 |
|
| 133楼: | >>参与讨论 |
| 作者: iQanalog 于 2005/7/13 2:01:00 发布:
还是我有一点钓鱼功夫 继续吧.... |
|
| 134楼: | >>参与讨论 |
| 作者: 北方老郎 于 2005/7/13 8:50:00 发布:
看看数字信号处理的书吧,仙农的采样理论和滤波器。 使用数字滤波器的话,很容易做到。如果处理器速度快,就用软件,否则就要用硬件。SB Live这样的声卡可能使用硬件实现的。其实,现在的计算机速度,用软件什么声卡都可以实现这个功能。 |
|
| 135楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/13 9:15:00 发布:
我就上面的一点东西,不明也得明,这样说法还不明的就是 牛皮灯笼,建议他改行别搞电子了!! |
|
| 136楼: | >>参与讨论 |
| 作者: xwj 于 2005/7/13 9:22:00 发布:
呵呵,看来飞船对语音了解不够或分析得不够哦 |
|
| 137楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/13 9:34:00 发布:
既然要的是高保真,把资料叠加或删除后包络线还原就是高保真, 包络线的识别用FFT分析是没法实现的,只能在程序内嵌智能识别算法!包络线的识别原理以上我已经说的很清楚了-->相位过零极值判断法! |
|
| 138楼: | >>参与讨论 |
| 作者: IceAge 于 2005/7/13 10:55:00 发布:
不懂不是你的错,但乱下断言就是你的不对了 呵呵,宇宙飞船看来还没有理解 fft 的工作原理, 我前面的帖子都白说了。 "FFT变换实质上是做了个固定而且已知的频率表,最终还是要用程序判极值“ 固定而且已知?这从何谈起。fft得到的是频谱(44k, 4096 --> 10Hz to 22kHz,解析度为10hz),无需判断峰值。 “FFT变换处理在此实在是多此一举,画蛇添足“ 说实在的,时域法只是在要求不高时的廉价解决方案。而频域法通过保持频谱基本不变,从而真正做到高保真,而且还有很多其他高级效果是mcu 用时域法根本无法做到的。有了vcd不能就说DVD多此一举 "包络线的识别用FFT分析是没法实现的", 包络线也是由包络基波及其谐波组成,可以由正弦波拟合,换句话说,频谱中包含了包络线的全部信息。 |
|
| 139楼: | >>参与讨论 |
| 作者: xwj 于 2005/7/13 11:16:00 发布:
人耳对声音的音调、音色变化非常敏感,而对幅度变化不敏感 人耳的特性对声音的音调、音色变化非常敏感,而对幅度变化不敏感 最最敏感的就是音色, 比如我们可以很轻易的分别是不同人在说话,对他的语气敏感,而对他的声音大小反映却并不敏感 现实中一个声音中插入一点别的频率很小的声音,人耳都可以分辨出来或感觉到,而假如这个声音仅幅度变化了一些,人耳却根本听不出来 人耳听觉还有个特性:对于增加的频谱特别敏感,会感到很刺耳,不和谐,对于缺失的频谱虽然能听出来,当时并不敏感,一般不对比不会觉察到 在变速变调处理后音波形明显会有很大变化,对于信号来说根本谈不上“高保真” 此时所谓的“高保真”是为了让耳朵听不出来,让耳朵听着舒服 变速“不变调”在变速的同时,保证基频不变这点设计的都能做到,关键在音色和幅度间的取舍 针对人耳的听觉特性。正确的选择明显应该选择频谱,而不应该选择幅度 只有调制频率比原是信号频率高很多是考虑包络线才有意义,此时才可以滤去调制频率 对于语音信号,谐波和基频、包络线的频率相差都不大,很难分离,此时一味考虑包络线是明显错误的 正确的做法是恢复频谱,并去除多出来的频谱!只要频谱(功率谱)正确,包络线是可以忽视的!这才是针对听觉的“高保真” 宇宙飞船 考虑包络线的方法恰恰与此背道而驰 所以只能说 宇宙飞船 还是没把握住要点, “对语音了解不够或分析得不够”了 |
|
| 140楼: | >>参与讨论 |
| 作者: xwj 于 2005/7/13 11:41:00 发布:
To 北方老郎:PC的硬软件之分针对的是是否需要CPU参与算法运算 PC的硬件、软件之分并不是指电路上的硬件,而是针对于是否需要CPU参与算法的运算,某个设备硬件实现某功能是指该设备可以单独的完成该功能,CPU只需与他交换参数,而不比参与该功能的运算 比如MODEM,我们知道有软猫、硬猫、半硬猫(半软猫) 在传统MODEM的内部,有两个独立的功能模块。一个是负责模拟/数字信号处理的信号处理模块,而另一块是用于数据流控制的控制模块。MODEM的控制模块负责提供MODEM必需的通讯协议、差错控制、维持连接以及数据压缩等功能。 在"硬"MODEM中,这些功能被固化到了MODEM上的控制芯片中。 "软"MODEM利用现在CPU强大的运算能力,用软件来接替原来MODEM控制模块的功能。这么做的首要目的是省掉MODEM的控制芯片及相关电路,从而降低制造成本;当然MODEM本身的信号处理模块是无法用软件代替的。 还有一种MODEM是介乎以上两者之间的是一种半软半硬的MODEM。这种MODEM没有处理器,却具有硬的"数据泵",复杂数据算法在卡上实现,简单的控制命令交给计算机处理。 这些MODEM除了本身的信号处理模块是无法用软件代替的,数据处理实际上都是软件完成的,只是设备和电脑CPU参与的程度不同罢了 “SB Live这样的声卡可能使用硬件实现的”实际上也是由声卡内部高速DSPEMU-10K1芯片软件运算完成的,只是他可以单独完成,针对CPU来说,这个硬件设备单独完成了该功能,CPU不需参与任何运算,所以这是个“硬件完成该功能”的设备 |
|
| 141楼: | >>参与讨论 |
| 作者: 潜艇8421 于 2005/7/13 19:58:00 发布:
晕! |
|
| 142楼: | >>参与讨论 |
| 作者: kanprin 于 2005/7/14 10:13:00 发布:
结果出来了,拍案叫好!小心的收入囊中!谢谢各位! |
|
| 143楼: | >>参与讨论 |
| 作者: YuanChong 于 2005/7/14 11:05:00 发布:
最重要的是实际应用效果 看了变么多高手的讨论,得益非浅。但我想注重的是实际应用的问题。据我所知 用DSP芯片做的音响器件,如移频器、均衡器、效果器等,很多都会有‘数码味’。按说都是在频域上作了处理,但效果不甚理想,为什么? |
|
| 144楼: | >>参与讨论 |
| 作者: xwj 于 2005/7/14 11:40:00 发布:
所谓的“数码味”是因为声音的量化造成的一些多余频谱导致的 听听128K的mp3(或者跟低码率的),再和cd比较一下,就知道什么是数码味了。不过cd也有数码味,不错,44.1K采样是可以精确描述22K以内的模拟信息,可对于声音来说,高于22K的信号仍然有(听不到,但那是一种感觉),所以,做cd之前,要先过低通才行,这就已经失真了。然后通过理想低通也可以将数字精确的还原成模拟信号,可理想低通是做不出来的,至于16bit的量化误差,也是失真的一个原因。这样看来,cd距离hifi还远的很…… |
|
| 145楼: | >>参与讨论 |
| 作者: xwj 于 2005/7/14 12:03:00 发布:
看看下面的几张图你就知道了 不同频率的信号给人不同的感觉,高频谐波给人的感觉就是干冷硬薄涩锐 采样的量化必然会把信号变成一个一个的阶梯,增加方波分量,方波的高次谐波(特别是相对与基频的奇次谐波)会让人听着非常难受,这种感觉是数码量化造成的,也是数码设备之后才有的,人们就把它称为“数码味” 通过通过理想低通可以高的频段切除,但哪来“理想”的呢?只能尽量减少这种感觉,好的设备能做到让一般人感觉不到罢了 那些做的不好的那就肯定“数码味”重呢 这是一个逐渐变弱的声音, 依次是32bit、16bit、8bit    |
|
| 146楼: | >>参与讨论 |
| 作者: stintair 于 2005/7/14 13:42:00 发布:
好几天没来了 看了一下这几天的贴,发现xwj认识的相对比较正确。 if(不用频谱分析) { 做出的产品=垃圾; } 提醒一下,采用FFT方法也是会失真的,跟窗宽度有关,只能在效果和计算量上折中。 各位,有点研究精神。 发贴之前先搞清楚三个问题:“理论依据是什么?为什么?实际应用有没有问题?” 向各位大侠致敬。 |
|
| 147楼: | >>参与讨论 |
| 作者: YuanChong 于 2005/7/14 13:44:00 发布:
谢谢xwj,还有一个问题 DSP处理信号,在很多领域都取得很好的效果,但音响尤其是HiFi,是一个非常主观的感觉,那么在现有的条件下(受器件、价格等因素限制)能否做出暖一些的效果呢? |
|
| 148楼: | >>参与讨论 |
| 作者: 潜艇8421 于 2005/7/14 15:40:00 发布:
请问xwj高人,那段声音由开始到结束的时间轴是多少? 是1ms,10ms,100MS,1000ms? |
|
| 149楼: | >>参与讨论 |
| 作者: YuanChong 于 2005/7/14 17:32:00 发布:
有感理论与实践 对工程师来说,理论是很重要的,但他毕竟不是搞理论研究的。更重要的是将理论在实践中应用的能力。所有的理论模型,都是在忽略了一些次要因素下建立的而当实际中此因素不可忽略时,变通的能力就很重要了。或许这就是所谓经验的重要吧。 |
|
| 150楼: | >>参与讨论 |
| 作者: 北方老郎 于 2005/7/14 19:30:00 发布:
xwj是数字信号处理高手 |
|
| 151楼: | >>参与讨论 |
| 作者: iQanolog 于 2005/7/14 20:43:00 发布:
真没完啊 |
|
| 152楼: | >>参与讨论 |
| 作者: pheavecn 于 2005/7/14 21:27:00 发布:
其实外国佬早就给出答案了。 还是要从理论上好好分析呀。 答案就在GoldWave软件的菜单:效果-->时间扭曲中。 大家自己看吧。 有宇宙飞船的方法...添加/删减法 有IceAge的方法...FFT法 效果大家可以自己判断. 想不到这个帖子我也能给出一个不错的答案呢. |
|
| 153楼: | >>参与讨论 |
| 作者: pheavecn 于 2005/7/14 21:30:00 发布:
贴图: 如何贴图呀?!! 为何连我这样的老用户都无法贴图了. |
|
| 154楼: | >>参与讨论 |
| 作者: pheavecn 于 2005/7/14 21:31:00 发布:
大家只有自己装个GoldWave去看了. |
|
| 155楼: | >>参与讨论 |
| 作者: pheavecn 于 2005/7/14 21:44:00 发布:
用GoldWave试着把一首音乐变快/慢. FFT效果相当不错的. 添加/删除法就勉为其难了. |
|
| 156楼: | >>参与讨论 |
| 作者: iQanalog 于 2005/7/14 23:37:00 发布:
真不明白,为什么要那么复杂?----我来终结!! 请教高手:声音的变速不变调是怎样实现的?? 有些学习机有播放调速功能(例如快、慢速播放),而它的音调却不变! 请问大虾们,这是什么样的原理呢?是否有源代码参考? 谢谢! 欢迎讨论。 _____________________________ 以我的浅见,楼主的主要目的是慢放快放。其实只是音频包络的延长或缩短。因此各位所说的方法显得太复杂了。其实,只要注意到这点,问题很容易解决的:就是设法延长或缩短包络就可以了。 ----这个要做到不难吧?只要适当地根据基频按照一定的速度比例截去或插入某些波段就可以解决问题。如果要实现“高保真”,那么注意平滑过度就可以了。再复杂一点,不过是根据基频和谐波取最小公倍数来进行截取或插入。那些过于复杂的算法还是收起来吧...... 这个观点,也许一时有人不理解。不过,可能许多人也不明白,为什么电子音乐(如电子琴),总有那么一点“电子味”一样,不仔细想想,也是不会明白的。 今天还有一点功夫要做,看看你们的理解到底能不能跟上,改天再说吧,如果一时无人给予明白解释的话。 各位回见,今天总算在到论坛以来发了个绝顶的好帖,具体问题你们去解决吧! 88,...... |
|
| 157楼: | >>参与讨论 |
| 作者: iQanalog 于 2005/7/14 23:44:00 发布:
不是吹牛吧? 飞船老兄在天上的触角可莫掉了下来给俺用哪...... |
|
| 158楼: | >>参与讨论 |
| 作者: iQanalog 于 2005/7/15 2:10:00 发布:
*^o^* 先简单解释 也算是修正一下吧。 以我的浅见,楼主的主要目的是想慢放快放。可是,让你分快慢来分别“呵--------”一声看看,其结果是什么?体会到了什么?轻呵重呵,长呵短呵----波形上只是音频包络的延长或缩短,因此各位所说的方法显得太复杂了。其实,只要注意到这点,问题是很容易解决的:就是设法延长或缩短包络就可以了。 |
|
| 159楼: | >>参与讨论 |
| 作者: lz1230lz 于 2005/7/15 10:01:00 发布:
不同意iQanalong的观点 实际应用中,光改变包络是不行的;尤其是低音部分,失真有时会很严重。 具体怎么才好,本人也在摸索中。请各位大虾踊跃发言,省得大伙走那么多冤枉路。 |
|
| 160楼: | >>参与讨论 |
| 作者: lz1230lz 于 2005/7/15 10:02:00 发布:
不同意iQanalong的观点 实际应用中,光改变包络是不行的;尤其是低音部分,失真有时会很严重。 具体怎么才好,本人也在摸索中。请各位大虾踊跃发言,省得大伙走那么多冤枉路。 |
|
| 161楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/15 10:13:00 发布:
真奇怪,包络线一样会失真吗?很多人就算知道我说的这个 简单的相位同步删除叠加原理,但是有没有这个能力写这个智能程序就是另一码事! |
|
| 162楼: | >>参与讨论 |
| 作者: YuanChong 于 2005/7/15 11:25:00 发布:
失真的定义 任何信号通过处理,都会失真。对测量仪器来说,fft的方法肯定最小。但若此信号是给人听的,则另当别论。让人觉得好听舒服的才是好的处理方法。(假若此信号是用来欣尝的话) |
|
| 163楼: | >>参与讨论 |
| 作者: YuanChong 于 2005/7/15 11:28:00 发布:
失真的定义 任何信号通过处理,都会失真。对测量仪器来说,fft的方法肯定最小。但若此信号是给人听的,则另当别论。让人觉得好听舒服的才是好的处理方法。(假若此信号是用来欣尝的话) |
|
| 164楼: | >>参与讨论 |
| 作者: 公民001 于 2005/7/15 15:58:00 发布:
受益匪浅 谢谢各位 |
|
| 165楼: | >>参与讨论 |
| 作者: iQanalog 于 2005/7/15 18:49:00 发布:
to lz1230lz:恰当地利用资源是关键 难道你没有细想,这个包络是如何产生的?有那么容易出现你说的那种失真吗?照你那么说,所谓的声音修剪程序,到底是什么回事啊?! 还是YuanChong说得好,用来欣赏的音频失真有时不足为奇,甚至要横加利用。例如MP3就是利用人们的听觉不敏感度来压缩编码的,它当然有失真,而且要人愿意接受这种失真,以便利用这种失真。明白吗?! 其实,这个问题的解决,在于复杂声音。如果是一个波形规整的的声音,简直是太简单了。当然,就是这样的一个声音,也不是没有问题的。比如,小提琴,一个长音基本是上很好的波形,可是,它的音头,则是比较复杂的。再比如,我们叫一声“啊........”,也有类似情形。 你说的低频失真,从听觉需要上说,可以说不存在或可以从根本上消除它,因为它只是低频,太容易对付了。问题是如果应用到一个频谱比较复杂和音频范围比较宽的时候(谐波多)是比较麻烦的。这涉及到声音的质量要求问题,或者是应用场合的问题。如果说,对于学习机那种音质要求的,你提出这样的问题,也太严谨了----过高的要求是一种浪费。早几天我指导一个MM实验,你想她遇到的问题是什么?竟然是她的示波器太高级了,让她不会看或读出数据来也不敢相信。这是一个实例,回个头说,如果交给你一台银河计算机上网,那是什么滋味啊?这说明如何根据应用场合,恰当地利用资源来解决实际问题是关键。 以欣赏和学唱歌曲为例,许多音并不用太费功夫去研究它。可是,如果你能细品到它的咽音,那么无论对你的欣赏还是感动程度,或是对你学唱仿唱的益处,却是极关键的。可是呢,这里并需要过低的音频出来,因为人声的最低频率相对乐音低频来说,也算是太高了(几乎可以列入中频)。基于此,对于学习机之类的要求,需要那么在乎所谓的低频吗?----就算它有你说的影响。 从飞船的意见看,我想他最明白我的意思。可我还要补充的是,由于谐波相位的原因,波形不同,但声音却可以是相同的,音频包络也并未真正改变。这一点,是研究开发声音非常有用的原理。 最后,要补充说明的是,我提出的思想并不是实现方法,但我相信,具体的方法归宿于它时,信号处理要容易,负担要减轻许多。 * - 本贴最后修改时间:2005-7-15 23:42:53 修改者:iQanalog |
|
| 166楼: | >>参与讨论 |
| 作者: 宇宙飞船 于 2005/7/15 20:43:00 发布:
包络线不失真,保真度当然很高了! 其实如果用数学描述程序的设计过程动作,实质上就是卷积的动作! |
|
| 167楼: | >>参与讨论 |
| 作者: iQanalog 于 2005/7/18 1:43:00 发布:
再改一下比较好:细品到他/她的咽音和气息 这样,更加细腻点----偶崇拜“妙处难学”。。。 _______ 可是,如果你能细品到它的咽音,那么无论对你的欣赏还是感动程度,或是对你学唱仿唱的益处,却是极关键的 |
|
| 168楼: | >>参与讨论 |
| 作者: also 于 2005/7/18 16:27:00 发布:
给个比较好理解的信号! 假设这样的一个扫频信号,起始信号为频率100hz的正弦波,之后每1S频率增加100hz,直到20Khz,幅度都是一样的。 要快放,那么就是让1S的时间变短些,假设为0.5S,那么信号就变成起始100hz,之后每0.5S信号频率增加100hz。 要慢放,就是让1S的时间更长些,假设为1.5S,那么信号就变成起始100hz,之后每1.5S信号频率增加100hz。 时域的波形大家都很好理解,频域上面其实也不难,就是信号的从100hz慢慢向20Khz移动,要是在winamp的频谱框中,就能看到一根竖线从左向右慢慢移动。 |
|
| 169楼: | >>参与讨论 |
| 作者: tathata 于 2005/7/18 17:46:00 发布:
Would you like to go further? We can achieve Frequency Shift by the way of DIGITAL and ANALOG. But who can help to advise if we can change the speed of AUDIO Signal Flow by the way of ANALOG like the DIGITAL does? Maybe impossible! |
|
| 170楼: | >>参与讨论 |
| 作者: chunyang 于 2005/7/18 18:45:00 发布:
建议总结一下,再开个新帖 |
|
| 171楼: | >>参与讨论 |
| 作者: iQanalog 于 2005/7/18 21:53:00 发布:
形象! 时域的波形大家都很好理解,频域上面其实也不难,就是信号的从100hz慢慢向20Khz移动,要是在winamp的频谱框中,就能看到一根竖线从左向右慢慢移动。 |
|
| 172楼: | >>参与讨论 |
| 作者: 21icligang 于 2005/7/19 15:33:00 发布:
顶的很立啊 |
|
| 173楼: | >>参与讨论 |
| 作者: iQanalog 于 2005/7/31 22:57:00 发布:
就这么结了? |
|
| 174楼: | >>参与讨论 |
| 作者: iQanalog 于 2005/8/8 20:28:00 发布:
真不明白 凭什么就结了?! |
|
| 175楼: | >>参与讨论 |
| 作者: IceAge 于 2005/8/8 20:46:00 发布:
哈哈,iQanalog 很搞笑。你还想怎么样 ? |
|
| 176楼: | >>参与讨论 |
| 作者: pheavecn 于 2005/8/8 22:38:00 发布:
老板,买单!!! |
|
| 177楼: | >>参与讨论 |
| 作者: d1276 于 2006/8/2 16:42:00 发布:
声调是跟频率有关系的,我想如果慢放的话,应该 声调是跟频率有关系的,我想如果慢放的话,应该是首先保持输出声音的频率和原来一样,变慢的话,中间逐个插入一些相同频率的音频信号,这样播放就变慢了,声调却没改变。 |
|
| 178楼: | >>参与讨论 |
| 作者: 兵临城下 于 2009/9/11 21:19:17 发布:
请问各位高手有没有变调不变速的软件?可以把男女声音互转的效果。 |
|
| 179楼: | >>参与讨论 |
| 作者: 戈多 于 2010/1/11 17:58:00 发布:
找音频编辑软件时偶然发现了这个帖子,刚开始看时大骇, 居然多年前就有如此多的人追捧热忠这种事情,我的意思是大家更多的不是在讨论一个学术问题,最后想要的也不是求得真正的学术答案,而是在享受这种好奇的感觉,乐得碰人的臭脚, 问题简单的话用不着当个玩意似的拿来讨论,问题难的话不是在这种环境这种地方能讨论明白的, 诸位"电子工程师"们实在是没有课题可研究了,跑到这来干这种正经事! |
|
| 180楼: | >>参与讨论 |
| 作者: 无语 于 2010/8/3 11:42:07 发布:
找声音变速不变调的时候找到这里 感觉很多人都是理论高手。。。添加删除法如何让一个声音不变 如何保持声音的完整性。。删除后声音的连接问题 有没想过波峰对波峰的情况或者波谷对波谷的状况。。 |
|
|
|
| 免费注册为维库电子开发网会员,参与电子工程师社区讨论,点此进入 |
Copyright © 1998-2006 www.dzsc.com 浙ICP证030469号 |