





引导滤波的软硬件协同加速器设计与实现
出处:电子技术应用 发布于:2017-11-16 15:20:42
摘 要:引导滤波算法被大量用于图像处理领域中,在去雨雪、去雾、前景提取、图像去噪、图像增强、级联采样等方面有很好的处理效果。但是对于实时应用,软件实现难以满足需要。提出了在SDSoC环境下利用软硬件协同开发策略实现引导滤波硬件加速。通过在SDSoC开发环境中调试C语言代码实现引导滤波算法,并将其中影响性能的函数用Xilinx公司开发的Zedboard开发版硬件实现。在设计中,采用了流数据的方法、PS(Processing System)端和PL(Programmable Logic)端协同开发策略,以及软硬件并行、流水线优化等优化方法,提高了加速器的整体性能。实验结果表明,提出的软硬件协同的引导滤波加速器加速比可达16。
0 引言
2010年HE K M等人提出了引导滤波(Guided Filter)[1]算法。该算法与双边滤波的相似之处就是同样具有保持边缘的特性,不同之处在于它还克服了去伪影的影响。该算法被大量用于图像处理领域中,在去雨雪[2]、去雾[3]、前景提取[4]、图像去噪、图像增强、级联采样等方面有很好的处理效果。
但是,随着处理图像的尺寸不断扩大,基于CPU处理的引导滤波算法越来越不能满足人们的需求,因此,王新磊等[5]用CUDA实现了引导滤波GPU加速。为使引导滤波能在嵌入式领域达到实时处理,本文提出了基于FPGA对引导滤波实现加速的方法。

1 引导滤波算法介绍
引导滤波理论的基础是局部线性模型。该模型认为:任意函数上的任意一点与该点邻近部分的点可以看成是线性关系,一个复杂的函数可以用很多局部线性函数来表示。若需要求出该函数上某一点的值,只需求出所有包含该点的线性函数的值,并求出这些线性函数值的平均值,这个平均值就是该函数上所求点的值。
2 引导滤波加速器设计
2.1 实验环境介绍
本文采用Zynq-7000系列的Zedboard开发板[6]作为硬件开发环境,其PS端提供了ARM Cortex-A9处理器、512 MB DDR3内存空间和外部存储接口。其PL端的XC7Z020 CLG481-1 EEP芯片提供了可编程逻辑阵列单元,为硬件加速提供了丰富的逻辑资源。本文采用SDSoC[7]作为软件开发环境,它是基于Zynq-7000全可编程芯片在嵌入式系统中的IDE(Integrated Development Environment)。
2.2 算法结构设计
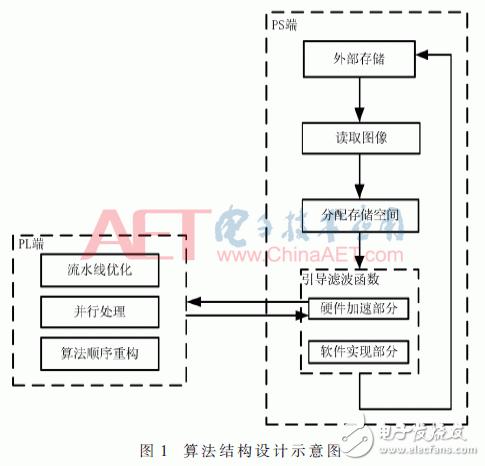
本文将单通道的图像数据存储在PS端的外部存储中,之后读取数据到内存中。为了获取的运算性能,在引导滤波函数调用前分配好算法需要的图像缓冲空间,将内存空间指针以参数形式传递给引导滤波函数,供其使用,之后PS端调用引导滤波函数。本文将引导滤波算法分为两部分,其中一部分是将对算法有较大影响的函数用硬件加速,硬件加速部分将数据传到PL端,PL端将其用硬件逻辑电路实现,对实现的硬件再通过流水线、并行处理和算法重构等优化方法对算法进行优化。处理完数据后,再将数据写回到PS端。终PS端将处理好的图像存储在外部存储中。算法结构设计如图1所示。
2.3 优化方法
2.3.1 流数据传输
为了获取PS端和PL端的传输性能,本文使用SDSoC开发环境中的sds_alloc函数[8]在PS端申请连续的物理地址作为图像缓冲区,并在硬件函数声明前插入指导编译器的参数#pragma SDS dada zero_copy(imgIn[0:rows*cols])和#pragma SDS data access_pattern(imgIn[0:rows*cols])命令来将图像数据转化为流数据[8]进行传输。
2.3.2 流水线优化
为了增加程序的并发性,流水线优化可以使当前操作没有完成之前就开始执行下一个操作。环境SDSoC的PIPELINE[8,10]优化指令可以对函数及循环进行优化。下面分别对函数的流水线和循环的流水线优化进行说明。
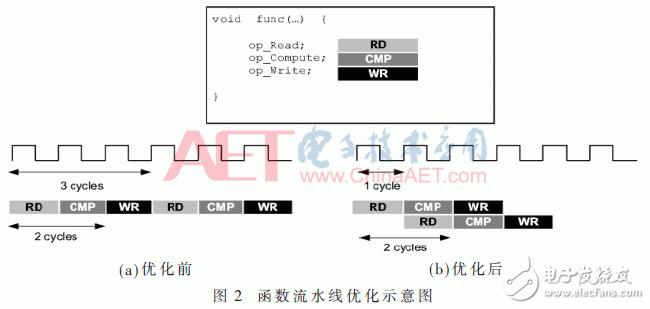
(1)函数的流水线操作
从图2可以看出,func函数需要3个时钟完成一组操作。若进行两组操作,在没有进行流水线优化的情况下,每次操作顺序执行,输出需要6个时钟;而经过流水线优化的func函数,每经过1个时钟就可以读取下一组数据,两组操作完成后只需要4个时钟周期就能够输出结果。由此可见,流水线优化可以提高函数的并发性,增加算法的效率。
(2)循环的流水线优化
从图3可看出,用循环来对图像像素进行处理,假设每个像素处理时间为30个时钟周期,若处理图像大小为512&mes;512,则未流水线优化前,需要的总时钟个数为7 864 320个时钟周期;流水线优化后,需要的总时钟个数为262 174个时钟周期,性能有了近30倍的提升。

2.3.3 并行处理
SDSoC环境提供了async和wait指令,使得程序员能够对硬件函数的同步方式进行控制。硬件开始工作后,PS端的async指令会交还CPU的控制权,继续执行PS端的任务,实现软硬件函数并行处理。通过这种方法,可以增加系统的并行性,提高算法的效率。wait命令用来同步数据,使得下一个函数能够成功应用上一个硬件函数的输出结果,防止程序死锁。
3 实验结果分析
本文输入单通道的.bmp格式文件为待处理图像,模板大小选择3&mes;3,引导图像和待处理图像为同一张图像,实验效果如图4所示。

其中,图4(a)为待处理图像和引导图像,图4(b)为经过软硬件协同加速器实现的引导滤波效果图,图4(c)为在PC上用OpenCV库纯软件实现的引导滤波效果图。通过对比可看出,经过软硬件协同加速器实现的引导滤波和在PC上纯软件实现的引导滤波在效果上基本相同。
为了比较本文提出的软硬件协同加速器的加速效果,分别测出了在PS端对不同大小图像实现引导滤波算法的帧率值和软硬件协同加速器对不同大小图像实现引导滤波算法的频率值。实验数据如表1所示。

4 结束语
本文实现了引导滤波的软硬件协同加速器,并利用开发环境SDSoC所提供的优化指令对硬件进行了性能优化。与CUDA实现的引导滤波相比,性能虽有所不及,但加速效果明显,并在低功耗及开发周期上优势大于CUDA。本文提出的软硬件协同加速器可直接用于内置CPU和FPGA的嵌入式系统中,缩短了嵌入式工程师开发周期,提高了系统整体性能。
版权与免责声明
凡本网注明“出处:维库电子市场网”的所有作品,版权均属于维库电子市场网,转载请必须注明维库电子市场网,https://www.dzsc.com,违反者本网将追究相关法律责任。
本网转载并注明自其它出处的作品,目的在于传递更多信息,并不代表本网赞同其观点或证实其内容的真实性,不承担此类作品侵权行为的直接责任及连带责任。其他媒体、网站或个人从本网转载时,必须保留本网注明的作品出处,并自负版权等法律责任。
如涉及作品内容、版权等问题,请在作品发表之日起一周内与本网联系,否则视为放弃相关权利。
- 参数提取法设计带通滤波器详细教程2018/5/28 11:21:50
- 滤波器电参数不良分析与维修2018/5/28 11:11:14
- 详细讲解:如何设计一个带通滤波器2023/6/20 17:33:35
- 有源滤波器设计工具比较2018/5/4 15:26:51
- 有源滤波器的相位响应第三部分:带通响应2023/6/21 16:25:53

- 英特尔数据存储如何操作和实现
- 什么是微动开关_微动开关有什么用_微动开关使用方法
- VCC,VDD,VEE,VSS在电源原理图中有什么区别?
- 低压配电系统设计规范_低压配电系统设计注意事项
- xEV 主逆变器电源模块中第四代 SiC MOSFET 的短路测试
- 光耦详细应用教程
- 定义绝缘耐久性评估的电压脉冲测试要求
- 采用沟槽MOS结构,使存在权衡关系的VF和IR相比以往产品得到显著改善 ROHM推出实现业界超快trr的100V耐压SBD“YQ系列”
- NOVOSENSE - 纳芯微推出车规级温湿度传感器NSHT30-Q1,助力汽车智能化发展
- Keysight - EV 电池设计创新:扩大续航里程、延长电池寿命


