





语音识别技术原理全面解析
出处:elecfans 发布于:2017-09-06 11:54:30
语音识别是以语音为研究对象,通过语音信号处理和让机器自动识别和理解人类口述的语言。语音识别技术就是让机器通过识别和理解过程把语 音信号转变为相应的文本或命令的高技术。语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都 有非常密切的关系。语音识别技术正逐步成为计算机信息处理技术中的关键技术,语音技术的应用已经成为一个具有竞争性的新兴高技术产业。
1、语音识别的基本原理
语音识别系统本质上是一种模式识别系统,包括特征提取、模式匹配、参考模式库等三个基本单元,它的基本结构如下图所示:
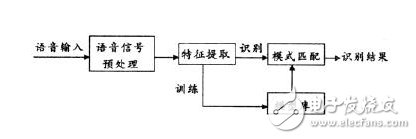
未知语音经过话筒变换成电信号后加在识别系统的输入端,首先经过预处理,再根据人的语音特点建立语音模型,对输入的语音信号进行分析,并抽取所需的特 征,在此基础上建立语音识别所需的模板。而计算机在识别过程中要根据语音识别的模型,将计算机中存放的语音模板与输入的语音信号的特征进行比较,根据一定 的搜索和匹配策略,找出一系列的与输入语音匹配的模板。然后根据此模板的定义,通过查表就可以给出计算机的识别结果。显然,这种的结果与特征的选 择、语音模型的好坏、模板是否准确都有直接的关系。
2、语音识别技术的发展历史及现状
1952年,AT&TBell实验室的Davis等人研制了个可十个英文数字的特定人语音增强系统一Audry系统1956年,美国普林斯 顿大学RCA实验室的Olson和Belar等人研制出能10个单音节词的系统,该系统采用带通滤波器组获得的频谱参数作为语音增强特征。1959 年,Fry和Denes等人尝试构建音素器来4个元音和9个辅音,并采用频谱分析和模式匹配进行决策。这就大大提高了语音识别的效率和准确度。
从此计算机 语音识别的受到了各国科研人员的重视并开始进入语音识别的研究。60年代,苏联的Matin等提出了语音结束点的端点检测,使语音识别水平明显上 升;Vintsyuk提出了动态编程,这一提法在以后的识别中不可或缺。
60年代末、70年代初的重要成果是提出了信号线性预测编码(LPC)技术和动态 时间规整(DTW)技术,有效地解决了语音信号的特征提取和不等长语音匹配问题;同时提出了矢量量化(VQ)和隐马尔可夫模型(HMM)理论。语音识别技 术与语音合成技术结合使人们能够摆脱键盘的束缚,取而代之的是以语音输入这样便于使用的、自然的、人性化的输入方式,它正逐步成为信息技术中人机接口的关 键技术。
3、语音识别的方法
目前具有代表性的语音识别方法主要有动态时间规整技术(DTW)、隐马尔可夫模型(HMM)、矢量量化(VQ)、人工神经网络(ANN)、支持向量机(SVM)等方法。
动态时间规整算法(Dynamic Time Warping,DTW)是在非特定人语音识别中一种简单有效的方法,该算法基于动态规划的思想,解决了发音长短不一的模板匹配问题,是语音识别技术中出 现较早、较常用的一种算法。在应用DTW算法进行语音识别时,就是将已经预处理和分帧过的语音测试信号和参考语音模板进行比较以获取他们之间的相似度,按 照某种距离测度得出两模板间的相似程度并选择路径。
隐马尔可夫模型(HMM)是语音信号处理中的一种统计模型,是由Markov链 演变来的,所以它是基于参数模型的统计识别方法。由于其模式库是通过反复训练形成的与训练输出信号吻合概率的模型参数而不是预先储存好的模式样 本,且其识别过程中运用待识别语音序列与HMM参数之间的似然概率达到值所对应的状态序列作为识别输出,因此是较理想的语音识别模型。
矢量量化(Vector Quantization)是一种重要的信号压缩方法。与HMM相比,矢量量化主要适用于小词汇量、孤立词的语音识别中。其过程是将若干个语音信号波形或 特征参数的标量数据组成一个矢量在多维空间进行整体量化。把矢量空间分成若干个小区域,每个小区域寻找一个代表矢量,量化时落入小区域的矢量就用这个代表 矢量代替。矢量量化器的设计就是从大量信号样本中训练出好的码书,从实际效果出发寻找到好的失真测度定义公式,设计出的矢量量化系统,用少的搜索和 计算失真的运算量实现可能的平均信噪比。
在实际的应用过程中,人们还研究了多种降低复杂度的方法,包括无记忆的矢量量化、有记忆的矢量量化和模糊矢量量化方法。
人工神经网络(ANN)是20世纪80年代末期提出的一种新的语音识别方法。其本质上是一个自适应非线性动力学系统,模拟了人类神经活动的原理,具有自 适应性、并行性、鲁棒性、容错性和学习特性,其强大的分类能力和输入—输出映射能力在语音识别中都很有吸引力。其方法是模拟人脑思维机制的工程模型,它与 HMM正好相反,其分类决策能力和对不确定信息的描述能力得到举世公认,但它对动态时间信号的描述能力尚不尽如人意,通常MLP分类器只能解决静态模式分 类问题,并不涉及时间序列的处理。尽管学者们提出了许多含反馈的结构,但它们仍不足以刻画诸如语音信号这种时间序列的动态特性。由于ANN不能很好地描述 语音信号的时间动态特性,所以常把ANN与传统识别方法结合,分别利用各自优点来进行语音识别而克服HMM和ANN各自的缺点。近年来结合神经网络和隐含 马尔可夫模型的识别算法研究取得了显着进展,其识别率已经接近隐含马尔可夫模型的识别系统,进一步提高了语音识别的鲁棒性和准确率。
支持向量机(Support vector machine)是应用统计学理论的一种新的学习机模型,采用结构风险化原理(Structural Risk Minimization,SRM),有效克服了传统经验风险化方法的缺点。兼顾训练误差和泛化能力,在解决小样本、非线性及高维模式识别方面有许多 优越的性能,已经被广泛地应用到模式识别领域。
4、语音识别系统的分类
语音识别系统可以根据对输入语音的限制加以分类。如果从说话者与识别系统的相关性考虑,可以将识别系统分为三类:(1)特定人语音识别系统。仅考虑对于专人的话音 进行识别。(2)非特定人语音系统。识别的语音与人无关,通常要用大量不同人的语音数据库对识别系统进行学习。(3)多人的识别系统。通常能识别一组人的 语音,或者成为特定组语音识别系统,该系统仅要求对要识别的那组人的语音进行训练。
如果从说话的方式考虑,也可以将识别系统分为三类:(1)孤立词语音识别系统。孤立词识别系统要求输入每个词后要停顿。(2)连接词语音识别系统。连接词输入系统要求对每个词都清楚发音,一些连音现象开始 出现。(3)连续语音识别系统。连续语音输入是自然流利的连续语音输入,大量连音和变音会出现。
如果从识别系统的词汇量大小考虑,也可 以将识别系统分为三类:(1)小词汇量语音识别系统。通常包括几十个词的语音识别系统。(2)中等词汇量的语音识别系统。通常包括几百个词到上千个词的识 别系统。(3)大词汇量语音识别系统。通常包括几千到几万个词的语音识别系统。随着计算机与数字信号处理器运算能力以及识别系统的提高,识别系统根据 词汇量大小进行分类也不断进行变化。目前是中等词汇量的识别系统,将来可能就是小词汇量的语音识别系统。这些不同的限制也确定了语音识别系统的困难度。
5、语音识别的应用
语音识别可以应用的领域大致分为大五类:
办公室或商务系统。典型的应用包括:填写数据表格、数据库管理和控制、键盘功能增强等等。
制造业:在质量控制中,语音识别系统可以为制造过程提供一种“不用手”、“不用眼”的检控(部件检查)。
电信:相当广泛的一类应用在拨号电话系统上都是可行的,包括话务员协助服务的自动化、国际国内远程电子商务、语音呼叫分配、语音拨号、分类订货。
医疗:这方面的主要应用是由声音来生成和编辑的医疗。
其他:包括由语音控制和操作的游戏和玩具、帮助残疾人的语音识别系统、车辆行驶中一些非关键功能的语音控制,如车载交通路况控制系统、音响系统。

未来随着手持设备的小型化,甚至穿戴化,各种智能眼镜,手表等层出不穷,当然找准市场突破口很重要,好的解决方案和系统设计参考也是必不可少的。
上一篇:制作电视天线放大器的方法
版权与免责声明
凡本网注明“出处:维库电子市场网”的所有作品,版权均属于维库电子市场网,转载请必须注明维库电子市场网,https://www.dzsc.com,违反者本网将追究相关法律责任。
本网转载并注明自其它出处的作品,目的在于传递更多信息,并不代表本网赞同其观点或证实其内容的真实性,不承担此类作品侵权行为的直接责任及连带责任。其他媒体、网站或个人从本网转载时,必须保留本网注明的作品出处,并自负版权等法律责任。
如涉及作品内容、版权等问题,请在作品发表之日起一周内与本网联系,否则视为放弃相关权利。
- HMI的基本类型是什么?2024/3/2 17:15:46
- GaN FET 如何成为音响发烧友的首选技术2023/12/28 17:29:50
- TI - 利用升压转换器延长电池使用寿命2023/11/10 11:17:11
- 电机逆变器:降低电器功耗2023/10/27 16:45:56
- RISC-V 张量单元声称可增强人工智能应用2023/10/25 14:02:29

- 英特尔数据存储如何操作和实现
- 什么是微动开关_微动开关有什么用_微动开关使用方法
- VCC,VDD,VEE,VSS在电源原理图中有什么区别?
- 低压配电系统设计规范_低压配电系统设计注意事项
- xEV 主逆变器电源模块中第四代 SiC MOSFET 的短路测试
- 光耦详细应用教程
- 定义绝缘耐久性评估的电压脉冲测试要求
- 采用沟槽MOS结构,使存在权衡关系的VF和IR相比以往产品得到显著改善 ROHM推出实现业界超快trr的100V耐压SBD“YQ系列”
- NOVOSENSE - 纳芯微推出车规级温湿度传感器NSHT30-Q1,助力汽车智能化发展
- Keysight - EV 电池设计创新:扩大续航里程、延长电池寿命


