





如果将8/16位微控制器升级成32位架构将会发生什么改变?
出处:电子发烧友 发布于:2018-08-28 14:16:32
特定应用的微控制器选型分类有很多种方法。从内核处理器类型和存储器总线系统入手是其中常见的一种。是选择8位、16位,还是32位架构,通常有以下几个参考标准:性能级别、可寻址存储器和系统成本。
客户有时还可能遇到各种需要多内核架构的应用,这种情况意味着用户不仅要花更多时间了解并掌握各种内核技术、外设编程技术和工具使用,还要在管理不同架构特性方面额外增加物流费用。
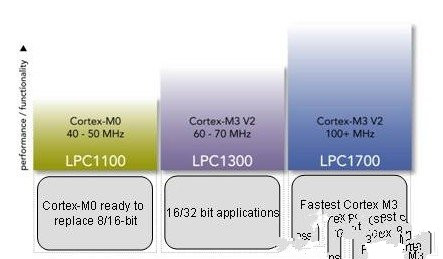
针对这一问题,恩智浦推出了基于32位ARM Cortex-M0处理器内核的LPC1100系列微控制器。该处理器是ARM公司Cortex-M系列尺寸的一款,具有32位架构性能、低功耗和超小封装等优点。LPC1100是恩智浦半导体大获成功的LPC1000微控制器系列的产品(参见图1),主要针对目前8/16位微控制器占主流的低成本应用的市场。
LPC1100完全具有围绕LPC1300和LPC1700微控制器(均采用Cortex-M3内核)建立的生态系统优势。从诸如UART、I2C和SPI等标准接口到高端的CAN和USB,LPC1100外设种类齐全。LPC1000生态系统包括多家供应商提供的编译器和调试工具、各种操作系统和软件。由于LPC1100系列微控制器Cortex-M0能够向上兼容M3内核,因此能够实现开发共享。
本文将针对过去8/16位微控制器的几个薄弱应用环节,重点介绍LPC1100的优势。此外,还将涉及LPC1100如何解决成本、功耗和代码大小等难题,以及如何提高传统8/16位微控制器应用领域的系统效率。
节能
对于门、窗或照明控制等家庭自动化应用领域,主要采用传感器连接到家庭自动化系统内部总线,这些总线和传感器从专用直流电路获取电流,大部分时间都处于工作模式。LPC1100在工作模式下出色的低功耗特点为此类应用提供了理想选择。
图2是一个从闪存执行代码并在RAM里操作动态数据的典型应用示例,显示了LPC1100在正常工作模式下几个内部系统模块的功耗情况。
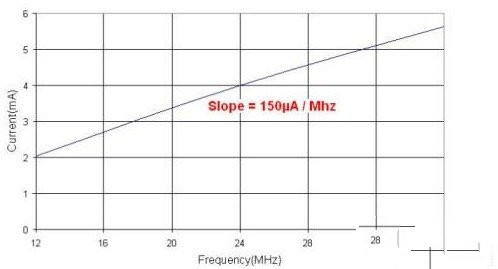
在电流消耗总量中,Cortex-M0内核和内部存储系统所占比重。尽管Cortex-M0内核的处理能力超强,但是采用该内核的LPC1100在无限循环运行时的平均耗电量仅为150μA/MHz左右。
预计在推出低功耗(LP)LPC1100新产品后,现有的LPC1100微控制器低功耗表现会得到进一步提升。工作模式耗电量有望降至130uA/MHz左右。
此外,由于M0内核采用32位架构,因此电流利用效率要高于8/16位架构。对于执行相同的计算任务,M0内核的实际运行速度可比8/16位微控制器低2-4倍,因此功耗要远低于8/16位微控制器。
对于“深度睡眠”或“深度掉电”模式,Cortex-M0内核的强大处理能力同样有用武之地,与8/16位架构相比,32位架构执行任务的时间更短,因此微控制器更多时间会处于低功耗模式运行。新型LP系列产品将大幅减少深度睡眠模式(2uA)和深度掉电模式(220nA)耗电量。
运算能力
LPC1100非常适合同时处理微控制器(MCU)基本任务和各种操作数(8位、16位或更高位)运算。嵌入快速的32位Cortex-M0内核(频率50MHz)并保持微控制器操作和编程灵活性(Cortex-M0 内核可以完全采用C语言)是代替16位混合系统的解决方案。
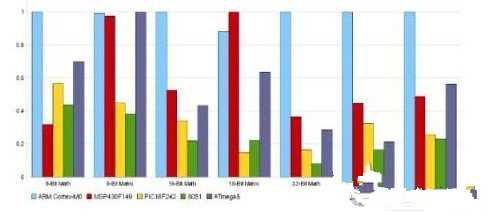
Cortex-M0微控制器可以轻松超越高端8/16位单片机。Cortex-M0内核的额定处理能力高达0.8DMIPS/MHz,是高端8 /16位单片机的2-4倍。由于DMIPS和MIPS有时并不能准确反映用户器件性能,因此图4根据一些通用的测试基准程序给出了各器件的相对性能。大多数常用Cortex-M0 Thumb2指令为单周期指令,所有8位、16位和32位数据传输在一个指令周期内完成。在8位和16位单片机中处理长字乘法运算通常要花很长时间,但由于Cortex-M0内核是32位架构,恩智浦在LPC1100中采用了32x32位硬件乘法器,通过MULS指令,成功地在一个指令周期内完成了两个32位字的乘法运算。
除法运算可通过软件完成,Cortex-M0对于各种操作数除法运算有同样出色的表现。
对于具体的应用,复杂的计算通常会涉及多次加法、乘法和除法。图5显示了一个复杂计算的执行时间,其执行条件是从闪存执行代码,采用浮点操作数共进行5次乘法、5次加法和1次除法计算。对于浮点运算,C语言代码可通过一个特定的Cortex-M0数学库函数做优化。
如果将8/16位微控制器升级成32位架构将会发生什么改变?
中断处理
微控制器的性能不仅要看执行速度,中断处理也一个重要方面。中断性能一般通过延迟时间和抖动(jitter)体现。延迟是指从中断事件产生到进入中断服务程序的时间,抖动用以描述延迟的变化。
Cortex-M0通过将中断控制器和内核紧密耦合,缩短了延迟时间。优先级中断延迟时间固定为16个时钟周期。中断控制器多可支持32个不同的中断源,包含一个非屏蔽中断输入。LPC1100对各种中断事件提供了专用中断向量,任何中断都会自动分配一个专用中断服务程序(ISR, Interupt Service Routine),无须软件处理。
为了缩短嵌套中断的延迟时间,LPC1100采用了一种集成机制,如果高优先级中断在低优先级中断进入服务程序前到达,可避免重新堆栈。此外,LPC1100还支持尾链功能(tail chaining),通过叠合异常出栈顺序以及随后出现的异常进栈顺序可直接进入ISR,缩短延迟时间。
系统成本
影响系统总成本有几个方面的因素,对于小型系统,内核和内存所占比重。
内核尺寸:Cortex-M0内核专门针对低成本应用开发,主要面向以往的8/16位小型微控制器架构市场。Cortex-M0内核的尺寸仅为Cortex-M3的1/4,参见图6。对于外设较少、Flash空间有限的小型系统,较小的内核可以减少芯片的整体尺寸。Cortex-M0逻辑门数量达到了经典的8位内核水平,却带来了更出色的处理能力,并为更强大的Cortex-M系列处理器提供向上兼容性。
闪存占用量小:储存应用程序代码所需的闪存尺寸是影响系统总成本的另一个重要因素。考虑到32位指令比8位指令性能更强,并且能代替多条8位指令,因此可以假设应用代码尺寸基本相同(不包括常数表)。不过,通过输入LPC1100的8位代码的实际测试结果看,应用代码尺寸要小很多,甚至可以达到50%以下。
ARM Cortex-M0执行Thumb指令集,包括少量使用Thumb-2技术的32位指令,参见图7。Thumb指令集是ARM Cortex-M3和ARM Cortex-M4支持的指令集的子集,并与之二进制编码向上兼容。
将ARM7TDMI的16位Thumb指令和部分Thumb-2功能强大的32位指令结合在一起使用,可以提高代码密度。编译器会选择是使用16位还是32位指令,终代码中两者可以完全共存。运行期间系统能够实现16位和32位代码无缝切换,无需像在使用ARM7TDMI时那样,需要专用指令。下表是一张Cortex-M0完整的指令集。
总体来看,LPC1100在低成本MCU市场具有很强的竞争力,其出色的灵活性和强大的性能将成为8位和16位架构占统治地位的各应用领域有力的竞争对手。LPC1100支持超小封装(16引脚CSP,2.5 x 2.5mm)以及易于操作的HVQFN和LQFP封装。该系列所有产品均支持UART、I2C和SPI等常见外设,并可在LPC1000系列其他产品上复用这些外设的驱动。此外,LPC1100还支持USB和CAN等高端外设,其驱动代码内嵌在ROM掩膜中, 因此Flash闪存可完全用于用户自己的应用程序。
客户有时还可能遇到各种需要多内核架构的应用,这种情况意味着用户不仅要花更多时间了解并掌握各种内核技术、外设编程技术和工具使用,还要在管理不同架构特性方面额外增加物流费用。
针对这一问题,恩智浦推出了基于32位ARM Cortex-M0处理器内核的LPC1100系列微控制器。该处理器是ARM公司Cortex-M系列尺寸的一款,具有32位架构性能、低功耗和超小封装等优点。LPC1100是恩智浦半导体大获成功的LPC1000微控制器系列的产品(参见图1),主要针对目前8/16位微控制器占主流的低成本应用的市场。
LPC1100完全具有围绕LPC1300和LPC1700微控制器(均采用Cortex-M3内核)建立的生态系统优势。从诸如UART、I2C和SPI等标准接口到高端的CAN和USB,LPC1100外设种类齐全。LPC1000生态系统包括多家供应商提供的编译器和调试工具、各种操作系统和软件。由于LPC1100系列微控制器Cortex-M0能够向上兼容M3内核,因此能够实现开发共享。
本文将针对过去8/16位微控制器的几个薄弱应用环节,重点介绍LPC1100的优势。此外,还将涉及LPC1100如何解决成本、功耗和代码大小等难题,以及如何提高传统8/16位微控制器应用领域的系统效率。
节能
对于门、窗或照明控制等家庭自动化应用领域,主要采用传感器连接到家庭自动化系统内部总线,这些总线和传感器从专用直流电路获取电流,大部分时间都处于工作模式。LPC1100在工作模式下出色的低功耗特点为此类应用提供了理想选择。
图2是一个从闪存执行代码并在RAM里操作动态数据的典型应用示例,显示了LPC1100在正常工作模式下几个内部系统模块的功耗情况。
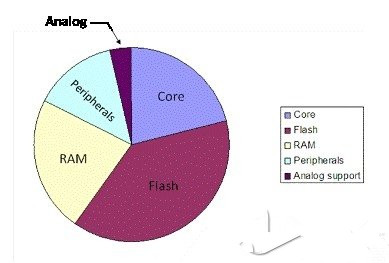
在电流消耗总量中,Cortex-M0内核和内部存储系统所占比重。尽管Cortex-M0内核的处理能力超强,但是采用该内核的LPC1100在无限循环运行时的平均耗电量仅为150μA/MHz左右。
预计在推出低功耗(LP)LPC1100新产品后,现有的LPC1100微控制器低功耗表现会得到进一步提升。工作模式耗电量有望降至130uA/MHz左右。
此外,由于M0内核采用32位架构,因此电流利用效率要高于8/16位架构。对于执行相同的计算任务,M0内核的实际运行速度可比8/16位微控制器低2-4倍,因此功耗要远低于8/16位微控制器。
对于“深度睡眠”或“深度掉电”模式,Cortex-M0内核的强大处理能力同样有用武之地,与8/16位架构相比,32位架构执行任务的时间更短,因此微控制器更多时间会处于低功耗模式运行。新型LP系列产品将大幅减少深度睡眠模式(2uA)和深度掉电模式(220nA)耗电量。
运算能力
LPC1100非常适合同时处理微控制器(MCU)基本任务和各种操作数(8位、16位或更高位)运算。嵌入快速的32位Cortex-M0内核(频率50MHz)并保持微控制器操作和编程灵活性(Cortex-M0 内核可以完全采用C语言)是代替16位混合系统的解决方案。
Cortex-M0微控制器可以轻松超越高端8/16位单片机。Cortex-M0内核的额定处理能力高达0.8DMIPS/MHz,是高端8 /16位单片机的2-4倍。由于DMIPS和MIPS有时并不能准确反映用户器件性能,因此图4根据一些通用的测试基准程序给出了各器件的相对性能。大多数常用Cortex-M0 Thumb2指令为单周期指令,所有8位、16位和32位数据传输在一个指令周期内完成。在8位和16位单片机中处理长字乘法运算通常要花很长时间,但由于Cortex-M0内核是32位架构,恩智浦在LPC1100中采用了32x32位硬件乘法器,通过MULS指令,成功地在一个指令周期内完成了两个32位字的乘法运算。
除法运算可通过软件完成,Cortex-M0对于各种操作数除法运算有同样出色的表现。
对于具体的应用,复杂的计算通常会涉及多次加法、乘法和除法。图5显示了一个复杂计算的执行时间,其执行条件是从闪存执行代码,采用浮点操作数共进行5次乘法、5次加法和1次除法计算。对于浮点运算,C语言代码可通过一个特定的Cortex-M0数学库函数做优化。
如果将8/16位微控制器升级成32位架构将会发生什么改变?

中断处理
微控制器的性能不仅要看执行速度,中断处理也一个重要方面。中断性能一般通过延迟时间和抖动(jitter)体现。延迟是指从中断事件产生到进入中断服务程序的时间,抖动用以描述延迟的变化。
Cortex-M0通过将中断控制器和内核紧密耦合,缩短了延迟时间。优先级中断延迟时间固定为16个时钟周期。中断控制器多可支持32个不同的中断源,包含一个非屏蔽中断输入。LPC1100对各种中断事件提供了专用中断向量,任何中断都会自动分配一个专用中断服务程序(ISR, Interupt Service Routine),无须软件处理。
为了缩短嵌套中断的延迟时间,LPC1100采用了一种集成机制,如果高优先级中断在低优先级中断进入服务程序前到达,可避免重新堆栈。此外,LPC1100还支持尾链功能(tail chaining),通过叠合异常出栈顺序以及随后出现的异常进栈顺序可直接进入ISR,缩短延迟时间。
系统成本
影响系统总成本有几个方面的因素,对于小型系统,内核和内存所占比重。
内核尺寸:Cortex-M0内核专门针对低成本应用开发,主要面向以往的8/16位小型微控制器架构市场。Cortex-M0内核的尺寸仅为Cortex-M3的1/4,参见图6。对于外设较少、Flash空间有限的小型系统,较小的内核可以减少芯片的整体尺寸。Cortex-M0逻辑门数量达到了经典的8位内核水平,却带来了更出色的处理能力,并为更强大的Cortex-M系列处理器提供向上兼容性。

闪存占用量小:储存应用程序代码所需的闪存尺寸是影响系统总成本的另一个重要因素。考虑到32位指令比8位指令性能更强,并且能代替多条8位指令,因此可以假设应用代码尺寸基本相同(不包括常数表)。不过,通过输入LPC1100的8位代码的实际测试结果看,应用代码尺寸要小很多,甚至可以达到50%以下。
ARM Cortex-M0执行Thumb指令集,包括少量使用Thumb-2技术的32位指令,参见图7。Thumb指令集是ARM Cortex-M3和ARM Cortex-M4支持的指令集的子集,并与之二进制编码向上兼容。
将ARM7TDMI的16位Thumb指令和部分Thumb-2功能强大的32位指令结合在一起使用,可以提高代码密度。编译器会选择是使用16位还是32位指令,终代码中两者可以完全共存。运行期间系统能够实现16位和32位代码无缝切换,无需像在使用ARM7TDMI时那样,需要专用指令。下表是一张Cortex-M0完整的指令集。
总体来看,LPC1100在低成本MCU市场具有很强的竞争力,其出色的灵活性和强大的性能将成为8位和16位架构占统治地位的各应用领域有力的竞争对手。LPC1100支持超小封装(16引脚CSP,2.5 x 2.5mm)以及易于操作的HVQFN和LQFP封装。该系列所有产品均支持UART、I2C和SPI等常见外设,并可在LPC1000系列其他产品上复用这些外设的驱动。此外,LPC1100还支持USB和CAN等高端外设,其驱动代码内嵌在ROM掩膜中, 因此Flash闪存可完全用于用户自己的应用程序。
上一篇:关于嵌入式系统的分类与特点
版权与免责声明
凡本网注明“出处:维库电子市场网”的所有作品,版权均属于维库电子市场网,转载请必须注明维库电子市场网,https://www.dzsc.com,违反者本网将追究相关法律责任。
本网转载并注明自其它出处的作品,目的在于传递更多信息,并不代表本网赞同其观点或证实其内容的真实性,不承担此类作品侵权行为的直接责任及连带责任。其他媒体、网站或个人从本网转载时,必须保留本网注明的作品出处,并自负版权等法律责任。
如涉及作品内容、版权等问题,请在作品发表之日起一周内与本网联系,否则视为放弃相关权利。
相关技术资料
- EPS Global - 谁需要嵌入式安全?2024/4/22 15:39:31
- 什么是嵌入式SoC2024/4/3 16:20:28
- EasyARM-i.MX283(7)A 默认供电方案2024/3/28 17:39:53
- EasyARM-i.MX283(7)A 的快速入门2024/3/27 17:29:30
- 非线性数字滤波器:用例和示例代码2024/3/14 16:34:20
技术分类
广告

热门技术资料
最新技术资料
- 英特尔数据存储如何操作和实现
- 什么是微动开关_微动开关有什么用_微动开关使用方法
- VCC,VDD,VEE,VSS在电源原理图中有什么区别?
- 低压配电系统设计规范_低压配电系统设计注意事项
- xEV 主逆变器电源模块中第四代 SiC MOSFET 的短路测试
- 光耦详细应用教程
- 定义绝缘耐久性评估的电压脉冲测试要求
- 采用沟槽MOS结构,使存在权衡关系的VF和IR相比以往产品得到显著改善 ROHM推出实现业界超快trr的100V耐压SBD“YQ系列”
- NOVOSENSE - 纳芯微推出车规级温湿度传感器NSHT30-Q1,助力汽车智能化发展
- Keysight - EV 电池设计创新:扩大续航里程、延长电池寿命


