





浅析移动GPU厂商的发展史及其技术
出处:电子发烧友 发布于:2018-09-13 13:50:42
人工智能的飞速发展,需要强大的算力作为支撑,这背后NIVIDIA可谓是当之无愧的功臣。NIVIDIA先进的GPU技术和优异的软件生态,使其在竞争中脱颖而出,成为市场霸主。目前人工智能在图像处理及语音识别领域的研究取得了很好的发展,在手机和安防领域也有很多产品落地。在落地过程中,依然会面临设备算力的问题,而移动端GPU则自然而然的进入了人们的视野。
移动端GPU厂商的发展史
在移动端GPU市场中,没有形成一家独大的竞争格局。目前主要的移动端GPU厂商有高通,arm和imaginaton。高通的adreno来自ATI的imageon,ATI早被AMD收购,后来高通收购了AMD的移动设备资产,取得了AMD的矢量绘图与3D绘图技术和相关知识产权。后来高通结合AMD的手机图形技术发展为自家的Adreno图形处理器。另一家移动计算的巨头ARM,ARM在移动CPU的市场地位可谓遥不可及,但是在GPU领域,它确是诸多厂商中的一家,他的GPU业务也并非一开始就拥有,而是后来组建的。其GPU技术来自一家名为Falanx的公司,这家公司是早起从挪威大学脱离出来的一个名为mali的研究小组的成员组建的,早定位于PC领域,失利后转向SoC GPU设计。随着SoC市场的不断壮大,以及移动计算的发展,ARM收购了Falanx,组建了自己的GPU事业部。一家,Imagination Technologies,这是一家专注于GPU技术的公司,早在桌面级GPU的竞争中失利,后来转战移动端,Intel,三星,苹果,联发科,展讯曾经都是他的客户,一度被认为是的移动GPU厂商。这家公司可谓命运多舛,曾经作为苹果的供应商,由于iphone的每代产品在图形性能方面都比arm公版的Mali GPU有优势,一度让Imagination风光无二,但是随着苹果宣布自研GPU,Imagination的股票出现了断崖式下跌,公司濒临破产。后来将其业务进行拆分,MIPS业务出售给Tallwood MIPS,而GPU业务则出售给中国背景的私募基金Canyon Bridge。这一收购也填补了国内在GPU领域的空白。
在市场占有率方面,由于ARM以及高通的捆绑销售,Imagination并无优势,但是鉴于在物联网以及人工智能领域,目前三家都还没有建立起强大的生态,因此未来谁能称雄并未可知。
在技术方面三家GPU厂商架构差异比较明显,而且对外披露都比较少,相比较来说Imagination发面对于技术方面会开放一些。
Imagination的GPU Rogue架构浅析
在关于GPU的宣传中很容易看到一个词core,而且高端GPU也都是成千上万的core。其实宣传中的core并非CPU上“核”的概念。而真正意义上的,应该是AMD GCN架构中的Compute Unit, NVIDIA Maxwell架构中的SMM以及PowerVR Rogue架构中的USC等。对应于编程语言,应该是OpenCL中的Compute Unit(简称CU)。而宣传中所谓的core,则是OpenCL中的ProcessElement(简称PE)。
目前GPU采用的是多层级的线程技术,硬件结构和软件概念的对照如下图所示:从硬件结构看,首先是GPU设备,叫做device;一个GPU包含多个CU,而每个CU又包含多个计算通道。从OpenCL的软件架构看,每个NDRange对应一个GPU设备,其包含多个work-group,而每个work-group必须在一个CU上执行,也就是说,每个CU可以执行多个work-group,但是每个work-group不可以拆分到多个CU上去执行;每个work-group包含多个work-item,一个计算通道执行一个work-item。
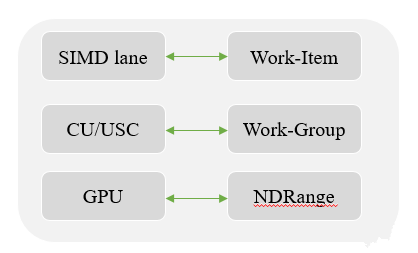
简单介绍一下计算通道,SIMD叫做单指令多数据流(Single instruction MultipleData),目前所有的GPU都术语SIMD,一般都是16路或者32路SIMD。
关于线程的调度,首先介绍一个概念,AMD的wavefront或者NIVIDIA的warp,这是指线程调度的单位,也就是说,在GPU中每次执行一个warp,一般一个warp包含32个线程;对于AMD显卡则是一个wavefront包含64个work-item。下文中对这一概念统称为warp,线程和work-item通用。在Rogue架构中每个warp也是包含32个线程。
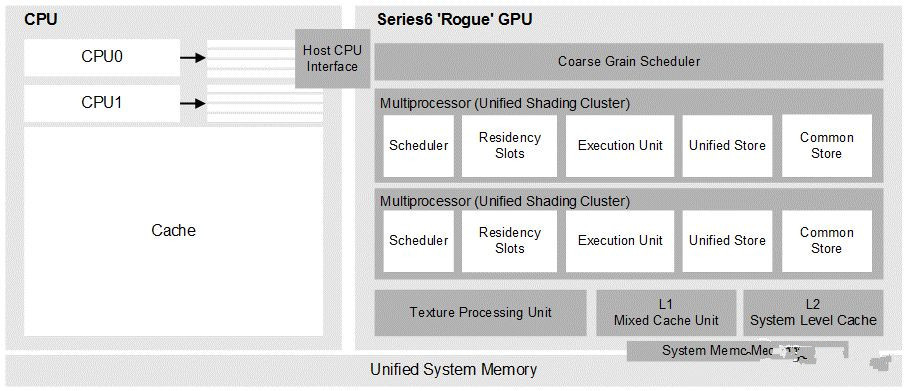
如下图所示,是Rogue架构的示意图,GPU中包含有多个USC(个数与产品型号有关),每个USC包含着色器,驻留槽,执行单元,存储器,纹理单元等等等。这样每个work-item在自己的生命周期中都包含自己的片上存储在Unified store中,shared local memory隐藏在common store中,这样每个USC都可以在warp之间进行零开销的上下文切换。
线程的执行过程如下图:
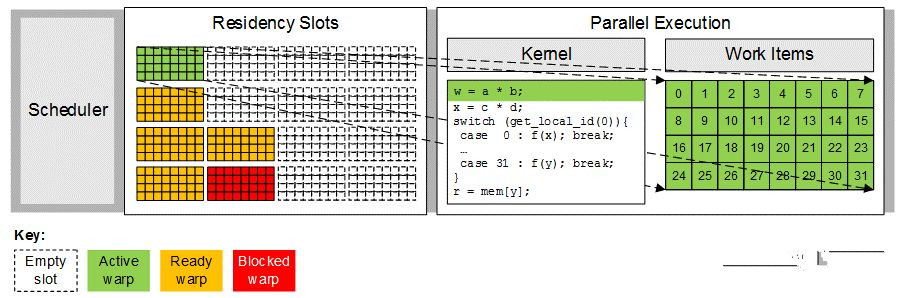
图中的Residency Slots中包含很多slot,每个slot代表一个warp,空的表示目前还没有部署warp。而部署了warp的slots一共有三个状态,绿色表示active,黄色表示ready,可以执行了,红色表示阻塞;active的warp接下来会在执行单元上执行,如图右侧所示,所有的32个work-item同时并行执行。Ready的会在下一个执行周期被调度执行;阻塞的则是因为读写等原因进入该状态。
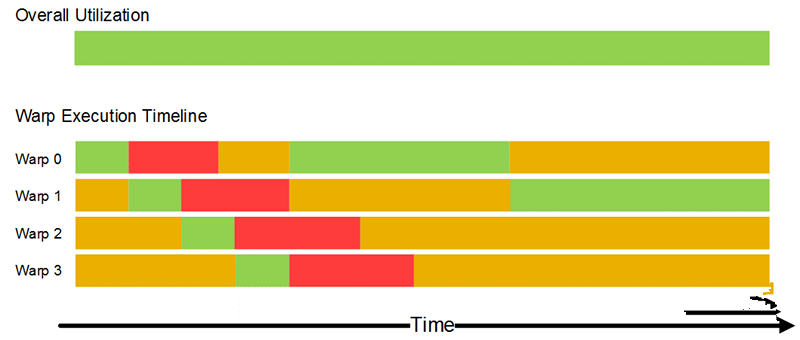
下图是USC中流水线示意图,其中包含4个warp的调度。Warp0首先被执行,warp0会一直执行到它进入阻塞状态,例如读写全局存储,此时调度器会停止调度warp0,开始执行warp1;因为warp中的所有工作项执行相同的kernel代码,因此就有相同的特性,例如同时进入阻塞;在warp2进入阻塞状态时,warp0读写结束,进入read状态;在调度器调度完warp3后,重新开始调度warp0。这样并发执行可以实现对内存访问延迟的隐藏。因此在编程实现中一般使用较大的工作组,来实现warp切换对内存访问的延迟(当然,这不是的,在实际中还要考虑寄存器等资源的消耗情况)。
下图展示了Rogue架构下得PowerVR Series7XT系列的架构图。
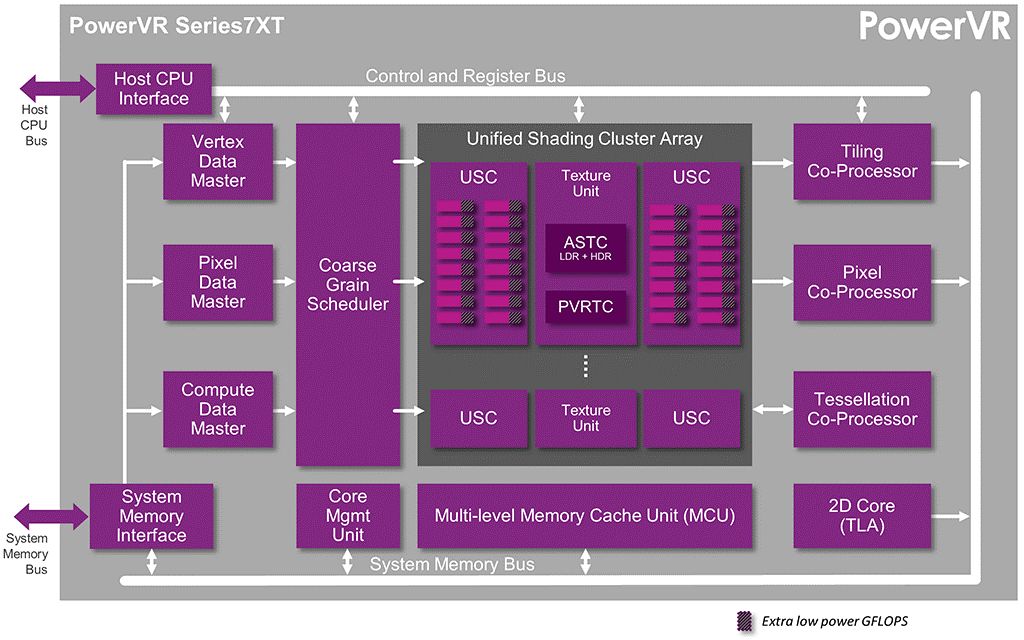
该系列的GPU拥有2到16个USC,因此具有100GFLOPS到1.5TFLOPS的可扩展性能。如下图展示了该系列GPU的USC架构。
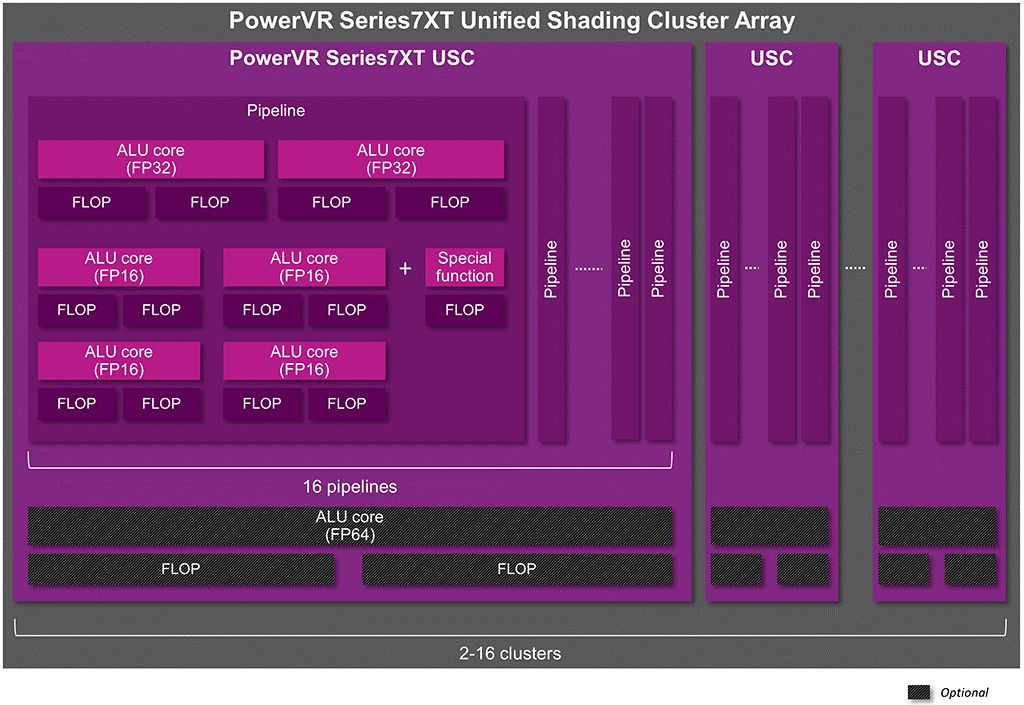
以GT7400为例,其拥有128个FP32ALU,256个FP16 ALU。每个USC中包含16个pipelines,每个pipelines中含有多个ALU。其中的SFU可以原生的处理FP16、FP32(上一代会全部推给FP32),因此这一代架构可以避免没有必要的高操作,提升了性能并降低了功耗。
目前Imagenition已经发布了的GPU架构Furian,该架构相对于多年来已成业界标杆的Rogue架构有了在性能方面有了更大的提升。
版权与免责声明
凡本网注明“出处:维库电子市场网”的所有作品,版权均属于维库电子市场网,转载请必须注明维库电子市场网,https://www.dzsc.com,违反者本网将追究相关法律责任。
本网转载并注明自其它出处的作品,目的在于传递更多信息,并不代表本网赞同其观点或证实其内容的真实性,不承担此类作品侵权行为的直接责任及连带责任。其他媒体、网站或个人从本网转载时,必须保留本网注明的作品出处,并自负版权等法律责任。
如涉及作品内容、版权等问题,请在作品发表之日起一周内与本网联系,否则视为放弃相关权利。
- I2C系统适应性引体向上2024/4/12 17:03:24
- RS-232 和 RS-485 有什么区别?2024/4/11 16:24:08
- spi接口的基本概念2024/4/10 17:52:03
- 总线收发器教程2024/4/8 16:19:32
- 什么是rj45接口?rj45接口有什么用2024/4/2 17:43:28

- 英特尔数据存储如何操作和实现
- 什么是微动开关_微动开关有什么用_微动开关使用方法
- VCC,VDD,VEE,VSS在电源原理图中有什么区别?
- 低压配电系统设计规范_低压配电系统设计注意事项
- xEV 主逆变器电源模块中第四代 SiC MOSFET 的短路测试
- 光耦详细应用教程
- 定义绝缘耐久性评估的电压脉冲测试要求
- 采用沟槽MOS结构,使存在权衡关系的VF和IR相比以往产品得到显著改善 ROHM推出实现业界超快trr的100V耐压SBD“YQ系列”
- NOVOSENSE - 纳芯微推出车规级温湿度传感器NSHT30-Q1,助力汽车智能化发展
- Keysight - EV 电池设计创新:扩大续航里程、延长电池寿命


