





基于TMS320DM642 的X264 视频编码器的优化
出处:xiang0909 发布于:2010-11-23 09:55:54
【摘要】简单介绍了TMS320DM642 数字信号处理器的硬件构成, 简要给出了DSP 平台的程序优化一般流程。着重研究了TMS320DM642 平台优化X264 视频编码器,包括算法与系统结构优化,乒乓缓存优化,循环体的优化以及DSP 汇编实现。
1 引言
在数字视频应用方案中,视频编码器是,其中编码器的硬件运算能力是系统实时性的保证,而视频压缩标准的高压缩比为编码器适应各种传输带宽信道提供了必要的保障。视频编码工程X264 是一款开源的、按照H.264 标准在PC 平台开发的视频编码器, 如果直接移植到TMS320DM642(以下简称DM642)平台,则实际的编码速度一般低于视频应用方案所需要的实时性要求。为了提高编码工程的编码速度, 需要对移植到DM642 平台的X264 进行优化, 整个优化的流程如图1所示。
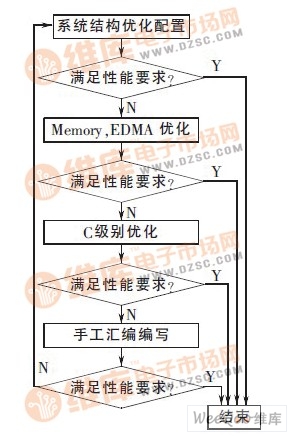
图1 优化流程图
2 DM642 硬件介绍
DM642 采用TI 开发的第二代高性能先进VelociTI技术的VLIW 架构VelociTI1.2,在主频600 MHz 下处理速度达到4 800 MI/s(兆指令/秒)。DM642 CPU 核内部具有64 个32 位通用寄存器和8 个独立的32 位运算单元(2 个乘法器和6 个算数逻辑单元), 确保每个周期能够提供4 个16 位介质访问控制(Medium Access Control,MAC)。
DM642 使用两级缓存L1 和L2。其中缓存L1包括程序缓存L1P 和数据缓存L1D;二级缓存L2 可配置为片内存储器、高速缓存或两者结合。
外设包括[4-6]:3 个可配置的视频端口;1 个10/100 Mbit/s的以太网控制器(EMAC);1 个管理数据输入输出(MDIO);1 个内插VCXO控制接口;1 个McASP0;1 个I2C 总线;2 个McBSPs;3 个32 位通用定时器;1 个用户配置的16 位或32 位主机接口(HPI16/HPI32);1 个PCI;1 个16 引脚的通用输入输出口(GP0),具有可编程中断/事件产生模式;1 个64 位IMI-FA,可以与同步和异步存储器的外围设备相连。
DM642 与传统的DSP 一样,采用哈佛结构,即把数据与程序分开存放于不同的存储区内,保证在DSP 的实际工作中,从程序存储区取指令与从数据存储区取运算数据是互相独立的, 另外在CPU 内部设计了8 个不同的处理单元, 可使在运行过程中,CPU 是按照流水线流程进行操作的。
3 DM642 平台优化方案介绍
3.1 算法和系统程序结构的优化
系统结构优化主要是合理安排程序中各个模块在DSP 的存储区间中所放的位置, 也就是解决存储区间的映射问题;在数据处理方面,尽量减少待处理数据的无谓搬移。算法优化主要体现在分析算法有没有更好更简单的替代方法,算法是否有某种对称性,可否采用更合适的数据结构等。在X264 的优化中,首先考虑系统结构的合理安排, 譬如程序到内存映射方面, 首先利用CCS的CODE_SECTION[9]伪指令把X264 中的9 个大的模块,依次映射到9 个大的子区间里面,把频繁使用到的DCT/IDCT 模块、QUANT/DEQUANT 模块、SAD/SATD 模块放到DM642 的片内存储区(L2 SRAM)中,把其他模块映射到片外存储区中。在数据访问方面,考虑到X264 编码分别为编码帧和帧间预测时的参考帧分配了存储空间,在移植的过程中, 存在着编码帧和参考帧的存放位置问题。从访问速度来看,片内存储区的访问速度要远远高于片外存储区的速度,但片内存储区的空间却要远远小于片外存储区,这样出现了访问速度与有限空间之间矛盾。考虑到实际编码流程中,编码的基本单元是16×16的亮度宏块加上2 个8×8 的色度模块, 这里用CCS 的DATA_SECTION[9]伪指令在DM642 的片内存储区(L2SRAM)中申请2 个大小为(16×16+8×8+8×8)的存储区,来存放编码像素值;用DATA_SECTION 伪指令在片内存储区内申请一些空间,临时存储编码过程中编码宏块的帧内预测模式信息、帧间预测运动矢量信息以及离散余弦变换系数和量化系数;,为了运动估计和帧内预测参考,给参考宏块分配一定存储空间。而整个当前编码帧和运动估计参考帧则放在DM642 映射的片外存储区。
3.2 EDMA 和乒乓缓存的优化
EDMA(Enhanced Direct Memory Access)是增强型直接内存访问的英文缩写。DMA 技术指的是在嵌入式处理平台或者大型计算平台上,外设与外设之间、外设与存储器之间、存储器与存储器之间可以在不需要CPU干预的情况下, 进行数据搬移和访问。这样可以保证CPU 在对一组数据进行运算时, 存储器把即将要处理的新的实验数据准备好,减少CPU 等待时间,特别是在一些需要进行大量数据搬移的情况下, 能够显着提高系统的运算速度。DM642 具备64 个EDMA 物理传输信道,能够保证数据在极短时间内,在DM642 外设的缓存区间和DM642 存储器之间进行搬移。DM642 的EDMA[10]主要有3种启动模式: CPU 启动,同步事件启动,外部事件启动。
CPU 启动指的是CPU 通过调用EDMA 的应用程序接口(Application Programming Interface,API) 去启动预先设置好的EDMA 搬移任务。同步事件启动一般指的是一个EDMA 信道完成了搬移任务,会产生激发信号,从而激发其他的EDMA 信道开始数据搬移。外部事件启动一般指的是DSP 的外设完成与外界的数据交换后, 激发EDMA信道进行数据搬移。
在对X264 进行EDMA 优化中, 采用双buffer 机制,也就是俗称的乒乓缓存(ping-pong buffer)机制。具体操作代码示例为:


示例中, 除了数据搬移中必需的数据存放源地址和目的地址之外,还定义了变量Ping_Pong 和DAT_ID。其中Ping_Pong 是一个标志变量,用来表示当前存放搬移数据的目的存储区是Ping 存储区还是Pong 存储区,DAT_ID 是正在进行的EDMA 搬移的句柄变量。在进入正式的编码循环体以前,EDMA 会事先把一个要编码的宏块像素值搬移到Ping 存储区(假设Ping_Pong=0 表示Ping存储区)。进入循环体以后,首先进行目标存储区的交替(Ping_Pong=1-Ping_Pong,此时Ping_Pong=1,表示Pong 存储区),接着等待前搬移是否完成(DAT_wait(DAT_ID)),如果前搬移完成,就可以立即开始下搬移,同时CPU 立即进行对本次搬移数据的处理。以后的操作类似,直至所有的宏块都完成编码,结束循环体。
3.3 循环体的优化
在X264 视频编码器中,循环体出现的频率比较高,而且往往循环体是在整个编码器中比较占用时间的部分。尤其是当出现循环体嵌套,或者循环体内部存在逻辑判断语句或者函数调用时,编译器一般不会对该循环进行优化。针对这些问题, 比较常用的方法有嵌套循环体内部循环展开,用条件操作符代替逻辑判断语句,使用内联函数,使用MUST_ITERATE 伪指令操作符[11-12],将大循环体拆成几个小循环体。笔者使用的循环体优化的例子代码为:

在上面示例中,伪指令MUST_ITERATE 主要是告诉编码器,本次循环总共要执行396 次,这样编译器就可以进行软件流水来优化这个循环。
3.4 编译器优化选项
在完成上述的手工优化后,接下来通过设置编译器选项来使用编译器优化,本文采用的编译器优化选项有:-pm(在程序级别进行优化),-o3(对文件级别进行强的优化),-op3(速度重要),-ml3(缺省情况下将全部数据和函数作为far 型)。
3.5 DSP 汇编优化
假如使用上述优化策略对编码工程进行优化后,编码器的速度还不能达到应用要求,就需要编写手工汇编程序。编写手工汇编程序之前, 首先要用CCS 的profile工具对编码工程进行剖析, 找出比较耗时或频繁调用的函数部分,把这些部分改写成汇编函数。
DSP 采用的是哈佛体系结构, 将数据和程序分开存放。大体上来说,编写汇编语言函数主要步骤为:把操作数从内存中取出来放到CPU 的寄存器中, 然后在CPU内部用不同的运算单元对寄存器里的操作数进行运算,把运算的结果存到内存中。其中,函数参数传递、函数返回值寄存器、条件寄存器、栈指针寄存器的保存都必须按照规定使用相应的寄存器,否则会出现错误。
在编写汇编语言的过程中要考虑下方面:1) 充分理解待编写的函数的逻辑功能。只有真正理解了函数实现的功能和具体的数据流程图, 才能使汇编语言的构架比较高效;2) 数据结构的选择和安排。由于DM642 允许数据打包处理,即一条指令可以同时对几个字节进行操作,这对于图像和视频处理非常有益, 所以能够打包处理的就尽可能打包处理;3) 寄存器的分配和指令的先后顺序。DM642 的CPU 有2 套完全对称的运算单元和寄存器。只要把操作数分别存、取到隶属于不同套的寄存器里面,采用不同的运算单元,合理安排指令的先后顺序,保证在资源不冲突的条件下尽量在一个周期内安排更多的指令,实现指令运行的高效性、并行性。
下面举一个SAD_4×4 的例子来说明上述各项是如何实现的。SAD_4×4 的C 语言版本的代码为:

SAD_4×4 的汇编语言版本的代码为:



完成汇编指令的编写后,进行汇编语言的调试。由于X264 工程比较大,如果直接在工程中调试,难度较大,所以在调试过程中建立一个小工程, 从文件中读出一段数据来测试汇编语言功能的正确性。具体的步骤是:采用单步调试的同时, 开启调试器CCS 里面的view memory 和view core registers 选项来观察相应的memory 和寄存器里面的值是否按照逻辑设计进行改变。如果结果不对,则考虑是否错误地使用了寄存器, 或者是没有等待足够多的延时周期, 或者是出于软件流水的目的错误地安排了指令的顺序,直到找出错误的地方。
4 小结
笔者首先分析了从PC 平台移植到DSP 平台后的X264 编码工程,其编码速率低,满足不了视频压缩实时性要求。接着从提高编码器的编码速度角度出发,对编码工程进行了优化,介绍了在实际中用到的几种DSP 平台优化方法:算法与程序系统结构的优化,EDMA 与乒乓缓存优化,循环体的优化,编译器优化和DSP 汇编。对CIF格式图像采用BASE_LINE 进行编码, 优化前X264 编码速度约为5~8 f/s(帧/秒),优化后的编码速度为20 f/s 左右,速度得到明显提升,基本能够实现实时编码。
参考文献:
[1]. TMS320DM642 datasheet https://www.dzsc.com/datasheet/TMS320DM642+_14462.html.
[2]. PC datasheet https://www.dzsc.com/datasheet/PC+_2043275.html.
[3]. PCI datasheet https://www.dzsc.com/datasheet/PCI_1201469.html.
[4]. far datasheet https://www.dzsc.com/datasheet/far+_1888220.html.
版权与免责声明
凡本网注明“出处:维库电子市场网”的所有作品,版权均属于维库电子市场网,转载请必须注明维库电子市场网,https://www.dzsc.com,违反者本网将追究相关法律责任。
本网转载并注明自其它出处的作品,目的在于传递更多信息,并不代表本网赞同其观点或证实其内容的真实性,不承担此类作品侵权行为的直接责任及连带责任。其他媒体、网站或个人从本网转载时,必须保留本网注明的作品出处,并自负版权等法律责任。
如涉及作品内容、版权等问题,请在作品发表之日起一周内与本网联系,否则视为放弃相关权利。
- Microchip 发布PIC16F13145系列MCU,促进可定制逻辑的新发展2024/4/23 15:34:17
- 什么是MCU2024/3/25 17:05:40
- 了解GD32单片机和STM32单片机2024/3/13 14:17:13
- STM32F103单片机概述2024/3/13 14:13:33
- 什么是DSP?DSP的分类2024/1/22 16:38:45



