





一种DCS模拟量在计算机中存储中的特点及分部压缩方法
出处:电子发烧友 发布于:2018-11-07 14:16:17
传统压缩方法对DCS 模拟量进行压缩效果不佳。要得到较好的压缩效果就要从模拟量在计算机中表示的方法入手。本文分析了DCS 模拟量在计算机中存储和表示方法及其特点,对原始数据进行预处理,使数据表现出较明显的冗余信息,然后对数据的不同部分,采用不同的压缩方法,每种压缩算法压缩模拟量数据的一部分。
与DCS 接口中,串行通讯是常见的接口方式。为了提高通讯效率,需要对通讯的数据进行压缩处理。DCS 模拟量的压缩方法中,常用整数表示工程量,即将模拟量的按其量程线性化处理为两字节正整数(0~65535),应用时再转换为工程量。这种方法由于要维护模拟量的量程表,不便于通信;另一类常用的压缩方法是采用LZW 等基于字典模型的压缩算法。模拟量数据是以单浮点数存放的,数据的冗余度很小,传统的压缩处理方法的压缩效果都不理想。
本文从模拟量在计算机中的表示方法入手,首先将模拟量预处理,再针对数据的不同部分采用不同的方法进行压缩,将压缩后数据组合起来。这样既充分考虑到了数据的特点,又充分利用了压缩方法的适应性。
1 模拟量的表示方法及特点
1.1 模拟量的表示方法
DCS 模拟量用单浮点数表示,占用4 个字节,可以到7 位有效数字。按文献[3] 标准(以下简称标准)表示。设一个浮点数R,可使用三元组{S,E,M}来表示:S 为符号位,用1 位表示。
S = 0 表示R 为正数,S = 1 表示R 为负数;E 为指数,用8bits表示。实际指数要经E - 127 计算后得到;M 为尾数,用23bits 表示。浮点数R 为S×1.M E(1 为隐含的一位尾数,不在M 中表示)。
1.2 模拟量的特点
数据压缩需要信息有足够的冗余度。以标准表示的模拟量不利于压缩。即便差值很小的数据,在计算机中表示结果差别很大,如1234.5 在计算机中用四字节表示为:68 154 80 0 ,而1234.6表示为:68 154 83 51,仅有符号位和指数位表示相同,尾数完全不同,这样就造成了压缩的难度。
现以200 个模拟量数据为样本分析其特点。样本数据随机产生,其范围为[0.0,1000.0].按照标准存储的数据从字符概率分布较平均,若用通用数据压缩方法压缩这些数据,得不到很好的效果。
虽然浮点数的信息冗余度很小,但若用其表示DCS 模拟量,仍有以下特点:
(1)各工程量数值多数大于零,因此标准表示中,符号位S 大多为零;
(2)各工程量的量程相差约为0.0001~10000 倍,因此标准表示中,指数差值约为-4 ~ 4 ;
(3)从数据考虑,工程量一般保留5 位有效数字即可。因此标准表示中,尾数部分有可压缩的信息。
2 模拟量的预处理
模拟量预处理的目的是为了产生更多的冗余信息,获得更好的压缩效果。通信时一般将模拟量按测点表以自然顺序排列。根据1.2 节的分析可知,若将模拟量按其三元组顺序排列,即:N 个模拟量数据,其自然排列顺序为{S1,E1,M1}、{S2,E2,M2}、…、{SN,EN,MN},共占用4N 字节。压缩前将模拟量序列按字节重新排列为:
S1S2…SNE1E2…ENM1M2…MN.因符号位S 为1 位,重新排列后将8个模拟量的符号位合并为1 字节。故重新排列后N 个模拟量共占用字节数为4N+N/8(+1) 字节。(括号中+1 字节表示N 不是8 的整数倍时总字节数+1)。
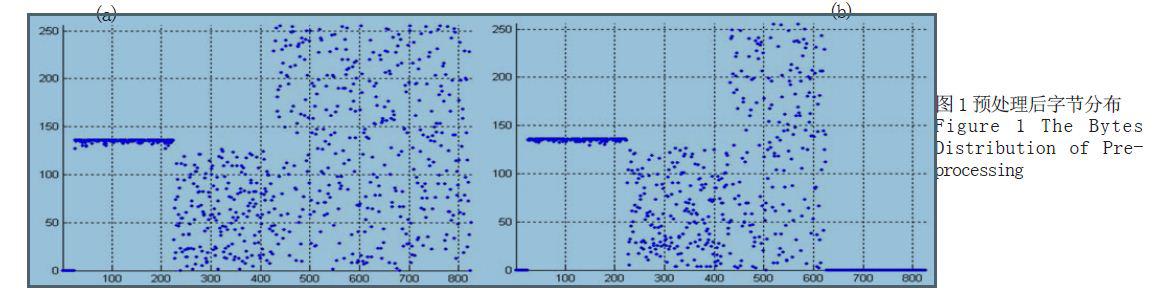
图1(a) 为样本数据经重新排列后字节分布情况。可以看出数据已呈现明显的规律性:部分数据[1,25] 为数据的符号,是样本数据的符号。样本数据均为正,因此由符号位构成的这部分数据全为零;第二部分数据[26,225] 为N 个样本数据的指数,根据1.2 节分析可知,各数据的指数差值大约在-4~4 之间,故有较大的压缩空间;一部分数据[226,825] 为N 个样本的尾数,呈随机分布。
次预处理是数据无损的。考虑到DCS 模拟量要求有5 位有效数字即可。根据信息理论,1 位十进制数可以表示log210 ≈ 3.32 位二进制数。单浮点数表示模拟量时,4 位二进制约可表示1 位十进制。因此,在满足DCS 系统要求的情况下,可以减少一个字节尾数。第二次预处理将尾数的字节置零,进一步提高数据的冗余信息。图1(b) 为第二次预处理后的字节分布情况。可以看出,相比次预处理,数据一部分[626,825] 全为零,可以更好地被压缩。
3 压缩算法的选择
3.1 压缩算法选择原则
压缩算法要根据原始数据的特点以及对速度、性能的综合要求来选择。模拟量的压缩应用在数据通信中,对速度的要求较高。
因此压缩算法不能过于复杂,运算量要小。
从预处理后的样本数据可以看出,每一部分数据的特点不同,因此选择压缩算法时应针对不同特点的数据采用不同的压缩算法来处理。部分数据(由符号位组成)为零(或绝大部分为零),可以采用游程编码(Run Length Encoding);第二部分数据(由指数组成)数值间相差不大,可用差分编码(Differential Encoding);第三部分数据(由部分尾数组成)随机性较大,压缩效果不明显,因此不进行压缩;第四部分数据(由字节尾数组成)均为零,可采用游程编码。
3.2 差分编码
差分编码又称相关编码。当源数据之间差值不大时,用数据间的差值代替源数据序列。较小的差值可以用较少的位数表示。本文用4 位二进制表示一个差值。
源数据中序列E1E2…EN 为数据的指数,其差值约在-4 ~ 4之间,用4 位二进制表示此差值:位用来表示差值的符号,其余三位表示差值,-7 保留。可表示的差值范围为-6~+7 ;若差值大于此范围,则不压缩,用原码输出。为了区分是差值输出还是原码输出,用保留的-7 表示下一字节为原码输出。N 字节源序列,若每一字节都可以用相邻差值来表示,其理想压缩比为1:(N/2+1)/N=1:0.5+1/N.
为样本数据差分编码压缩后字节分布。可以看到,源数据中表示指数的部分已经被有效压缩。样本数据由825 字节压缩到726 字节,实际压缩率为88.0%.
3.3 游程编码
游程编码的思路是:若数据项d 在源数据中连续出现n 次(n称为重复因子),则在输出流中以nd 代替n 个重复项d.游程编码也可能出现压缩比大于1 的情况。为了区分输出项是重复因子还是被压缩数据,规定当重复因子n ≥ 3 时,输出ddd(n-3) ;n < 3时,输出n 个d,即不压缩输出。另外重复因子3 ≤ n ≤ 255,若数据项d 重复次数大于255,则要重新进行游程编码。设源数据长度为N,包含M 次重复,每次重复平均长度L,则游程编码压缩比为1:(N-M×(L-4))/N.
样本数据经预处理后部分(由符号位组成)和第四部分(由位尾数组成)可以用游程编码。这部分数据可以获得很高的压缩比。部分理想压缩比为1:4/25=1:0.16 ;第四部分理想压缩比为1:4/200=1:0.015.
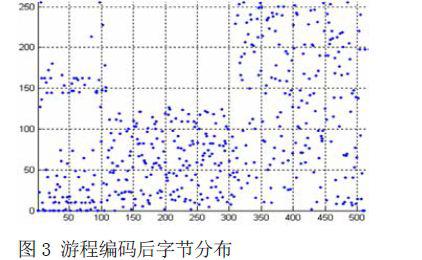
图3 为经游程编码压缩后的数据分布图。由上差分编码压缩后的726 字节压缩至510 字节,实际压缩比为1:0.70.
4 结论
200 个样本数据经预处理,对一部分数据进行差分编码、对另一部分数据进行游程编码,终有510 个字节。因此综合压缩比为1:510/800 ≈ 1:0.64,节省约36% 的空间。由于样本数据的随机性,因此可以推广到一般情况。得到以下结论:
(1)分部压缩方法可以获得约1:0.64 的压缩比;
(2)分部压缩方法为二级压缩算法构成。分别针对模拟量中不同信息类型的数据进行分部压缩;
(3)差分编码和游程编码的算法的复杂度低,其时间复杂度和空间复杂度均为O(n),故算法效率很高。
(4)压缩过程未涉及到数据的工程特性,因此算法可推广至工业过程控制领域,具有一定的实用价值。
版权与免责声明
凡本网注明“出处:维库电子市场网”的所有作品,版权均属于维库电子市场网,转载请必须注明维库电子市场网,https://www.dzsc.com,违反者本网将追究相关法律责任。
本网转载并注明自其它出处的作品,目的在于传递更多信息,并不代表本网赞同其观点或证实其内容的真实性,不承担此类作品侵权行为的直接责任及连带责任。其他媒体、网站或个人从本网转载时,必须保留本网注明的作品出处,并自负版权等法律责任。
如涉及作品内容、版权等问题,请在作品发表之日起一周内与本网联系,否则视为放弃相关权利。
- 英特尔数据存储如何操作和实现2024/4/26 17:40:38
- TI - 电池储能系统需要克服的三大设计挑战2024/4/24 15:46:55
- ram与rom的主要区分2024/4/12 17:48:19
- 什么是储能电池2024/4/3 17:34:46
- 一文解析HBM技术原理及优势2024/3/29 17:53:22



